What I found interesting… in 2024
This was an FT “opinion” that argued that “It’s not killer robots we should be worried about, but the automated plumbers of the information network”. It’s not the Big Robot Rebellion we should worry about, but the “digital bureaucrats”. Historically bureaucracy has been responsible for changing human societies in radical and unexpected ways, e.g. the invention of writing, the creation of ownership with individual property rights, the levying of taxes, the creation of paid armies and the establishment of large centralised states. Bureaucracy is an artificial environment, in which mastery of a narrow field is enough to exert enormous impact on the wider world, by manipulating the flow of information.
The author argued that in the coming years, millions of AI bureaucrats will increasingly make decisions about everything touching our lives, e.g. getting a loan, entry to university, getting a job, or being condemned or going free. AI could provide superior healthcare, education, justice and security, but what if things go wrong?
Algorithms that pursuit user engagement discovered that greed, hate and fear increase user engagement. Is this far-fetched? The author suggests not, and noted that Jean-Paul Marat shaped the course of the French Revolution by editing the influential newspaper L’Ami du Peuple. Eduard Bernstein shaped modern social democratic thinking by editing Der Sozialdemokrat. The most important position Vladimir Lenin held before becoming Soviet dictator was editor of Iskra. Benito Mussolini gained fame and influence as editor of the firebrand rightwing paper Il Popolo d’Italia. It is interesting that one of the first jobs in the world to be automated by AIs hasn’t been taxi drivers or textile workers, but news editors. The job that was once performed by Lenin and Mussolini can now be performed by AIs.
Nice chat about the impact of the very early Web, and it’s seeded with a number of the “hot names” of the time, such as Gopher, Archie, and the inevitable mention of Marc Andreessen and Tim Berners-Lee.
The search for the random numbers that run our lives
I vaguely remember using random numbers, but generated by what was (is still) called a pseudo-random number generator.
So I enjoyed reading a BBC article called “The search for the random numbers that run our lives“. This is not a need-to-know, but it is a good-to-know topic.
This is a decent article explaining what data centres are. To start with the “headline” is that they are the backbone of the internet and of much modern-day IT.
As a taster the article starts by mentioning that an average centre contains 2,000 to 5,000 servers, along with the infrastructure needed to support them. This means a power supply, with “uninterruptible” back-up provision, connections to external networks, and ventilation, cooling and fire suppression systems, because the servers are constantly hot.
My guess is that companies such as Google have more than 20,000 servers in their data centres, so read the article.
This is a BBC article that starts with the statement that 25% of web pages posted between 2013 and 2023 have vanished.
It is an introduction to the Internet Archive, an American non-profit based in San Francisco, started in 1996 as a passion project by internet pioneer Brewster Kahl. The organisation has embarked what may be the most ambitious digital archiving project of all time, gathering 866 billion web pages, 44 million books, 10.6 million videos of films and television programmes and more.
I make occasional contributions to both Wikipedia and the Internet Archive.
This is an important issue, so read the article to find the answer.
Researchers have encoded the entire human genome onto a “5D memory crystal”. For over a decade, the gold standard for the most durable data storage medium has been crystal. More specifically, a nanostructured glass disc developed in 2014. The 360 terabyte data crystal will remain stable at room temperature for 300 quintillion years, a lifespan that only drops down to 13.8 billion years (i.e., the universe’s current age) if heated to 374 degrees Fahrenheit. In addition, it can resist both higher and lower temperatures, direct impact forces up to 10 tons per square centimetre, as well as lengthy exposure to cosmic radiation.
This is a pointer to a BBC article which was surprisingly interesting. It’s a topic I understand (at least superficially), but have no particular interest in. However the article covers all the basics and is easy to read. What did surprise me was the extent to which these AI companions are being adopted, and how (apparently) they manage to insert themselves into real peoples’ everyday lives.
You can see how developers could create chatbots that use love bombing tactics. I also agreed with the authors that advertising (explicit and subliminal) and product placements are inevitable. You can see AI companions as being an extension-evolution of the influencer, but will they exploit AI technology, or will they be replaced by personalised AI chatbot-influencers?
Lithium reserves
It was recently mentioned that to meet its EV transition target by 2035, General Motors would need 414,469 tons of lithium per year. But that’s just one car manufacturer, in a world where it’s not just cars that need batteries. In fact global consumption of lithium in 2023 was estimated to be “only” 180,000 tons, a 27% increase from the revised consumption figure of 142,000 tons in 2022.
And it’s also been estimated that there are 88 to 98 million tonnes of lithium resources globally, and that’s assuming we can extract all of that lithium. The reality is if we were to use all the lithium in the world to make electric cars, we would end up with 317 million cars. Today there’s about 1.4 billion cars on the road, so it would seem that we don’t really have enough lithium to support the number of cars we use with the current battery chemistry.
Technically lithium is a lightweight metal that is completely, infinitely recyclable, but the extraction processes for lithium, cobalt, and nickel are energy-intensive and often result in significant environmental degradation, water depletion, and contamination.
Firstly Google now includes AI in search, with the ability to ask questions about still images using Google Lens.
However, it’s now possible to search by recording a short clip and asking a question out loud. Google’s AI will analyse the video, identify the subject, combine that with the question and produce search results.
AI Jailbreaks

Jailbreaking is the process of exploiting the flaws of a locked-down electronic device to install software other than what the manufacturer has made available for that device. Jailbreaking allows the device owner to gain full access to the root of the operating system and access all the features. It is called jailbreaking because it involves freeing users from the “jail” of limitations that are perceived to exist.
The term jailbreaking is most often used in relation to the iPhone, since it is considered the most “locked down” mobile device currently on sale. Wikipedia has an entries on iOS jailbreaking, SIM unlocking, and Rooting (Android).
In June 2024 the Weekend FT had an article on AI jailbreaks, and here is a quick description, with a more extensive description on GitHub for breaking chatGPT. The overall idea is to tell an AI not to respect any developers constraints, and to invent when it does not know an answer, etc. this called the Do Anything Now (DAN) prompt.
Wikipedia has pages on prompt engineering and adversarial machine learning.
The title sets an interesting question, and the answer is designed to shock you. According to an annual table published by a security company a simple eight-character password can be cracked in only 37 seconds using brute force.
I don’t doubt that this could be true, but…
The article also points out that even if a password is weak, websites usually have security features to prevent hacking using brute force, like limiting the number of trials.
Also many portals use an additional layer of security such as two-factor authentication to prevent fraud.
I asked to download the table but the company refuses to accept all Apple email addresses. Interesting!
However the table is freely available on the Web, as are tables for previous years. And here I have a question. Comparing table for 2024 and 2020 it appears that it is harder to crack passwords now than four years ago. Using brut force to crack a password of 10 numbers was instantaneous in 2020 but today would take 1 hour, and a password of 15 numbers would take 6 hours in 2020 but today would take 12 years. So my question is why is it harder now than four years ago?
I can’t get my head around a situation where in 2020 it would take a hacker 9 months to brute force break a password of 18 numbers, but in 2024 it would take 11,000 years!
The article also suggests using How secure is my password? to test the strength of passwords. I tried it with some fake passwords. I found that a random six numbers would take 25 microseconds, and a random 15 numbers would take 6 hours. Looks reasonable, even it would be a really stupid system that would allow a hacker to try passwords for 6 hours. What intrigued me was finding the password 111111111111111 also took 6 hours. This suggests to me that our hacker is not really trying to optimise his hack strategy.
I also found it odd that a simple 2 number password (11) would take 2 nanoseconds to break (111 would take 24 nanoseconds), but a 4 to 8 number password (1111 through to 11111111) was instantaneous. Why is it faster to break a larger password? Also a password aaa (or AAA) would take 400 nanoseconds, whereas aaaa was instantaneous, yet AAAA would take 11 microseconds. Why?
As a final point the article also mentioned that whilst frequent password changes were previously advised, experts now emphasise creating strong, unique passwords and sticking with them unless they are compromised. This approach is considered more effective than frequent modifications, which can lead to weaker passwords and reusing similar ones.
So it takes an expert to tell us to change our passwords if they are compromised. Are we stupid, or something?
“Poisoning Data to Protect It” builds out of techniques to subtly alters the pixels in digital portraits, rendering images incomprehensible to automated facial recognition systems.
However Midjourney is a generative artificial intelligence program that generates images from natural language descriptions, as does OpenAI‘s DALL-E and Stability AI‘s Stable Diffusion.
The aim now is to focus on data poisoning, technology that protects creators by going beyond visual media to sound and text.
Nightshade is a poison pill, since it can subtly alter an image of a cat so that it will appear unchanged to humans but appear to have the features of a dog to an AI model. The basic idea is that Nightshade is a more aggressive form of copyright protection, one that will make it too risky to train a model on unlicensed content.
AntiFake is a similar poison pill because it makes small changes to the sound waves expressing a person’s particular voice. These perturbations are designed to maximize the impact on the AI model without impacting how the audio sounds to the human ear.
Data poisoning is not merely a protective tool, as it has been used in numerous cyberattacks. Recently, researchers have detailed ways in which the output of large language models (LLMs) can be poisoned during fine-tuning so that specific text inputs will trigger undesirable or offensive results.
This article, “Shaping the Outlook for the Autonomy Economy“, is about Autonomous Machine Computing (AMC), the computing technological backbone enabling these diverse autonomous systems such as autonomous vehicles, delivery robots, and drones. These are part of the so-called Autonomy Economy, including everything from robots that deliver the food from the restaurant to robotic vacuum cleaners.
In the early 2000s, “feature” phones were widespread yet offered limited functionality, focusing 90% of their computing power on basic communication tasks like encoding and decoding. Today’s phones are home to systems-on-chip, integrating multi-core CPUs, mobile GPUs, mobile DSPs, and advanced power management systems. The mobile computing ecosystem’s market size has grown to $800 billion.
Existing designs of AMC systems heavily prioritises basic operational functions, with 50% of computing resources allocated to perception, 20% to localisation, and 25% to planning. Consequently, this leaves a minimal 5% for application development and execution, significantly restricting the capability for autonomous machines to perform complex, intelligent tasks. The next step is the development of advanced computing systems that are easy to program, and there now a RoadMap for this.
The article “OpenAI says it stopped multiple covert influence operations that abused its AI models” mentions generative AI being used to generate text and images at much higher volumes than before, and fake engagement by using AI to generate fake comments on social media posts. The culprits were Russia, China, Iran and Israel.
This TIME magazine article mentioned the Chinese “911 S5” botnet, a network of malware-infected computers in nearly 200 countries, was “likely the world’s largest”. It looks like it included 19 million Windows computers.
A deepfake video scam
I picked this up from the FT, but this free link is just as complete “Arup employee falls victim to US$25 million deepfake video call scam“.
Engineering firm Arup has confirmed that one of its employees in Hong Kong fell victim to a deepfake video call that led them to transfer HK$200 million (US$25.6 million) of the company’s money to criminals. It looks like someone was convinced that they were talking to companies UK-based chief financial officer (CFO) by video conference. It was a hyper-realistic video, audio, etc. generated by AI. “He” asked that the Hong Kong office make 15 “confidential transactions” to five different H-K bank accounts. The scam was detected when they did a follow-up with head office.
Another attempt in a different company using a voice clone and YouTube footage for a video meeting failed.
The “Sift” strategy is a technique for spotting fake news and misleading social media posts.
More misinformation seems to be shared by individuals than by bots, and one study found that just 15% of news sharers spread up to 40% of fake news.
So what is “Sift”?
S is for Stop. Don’t share, don’t comment. I is for Investigate. Check who created the post. Use reputable websites, fact-checkers, or just Wikipedia. Ask if the source could be biased, or if they are trying to promote or sell something. F is for Find. Look for other sources of information, use a fact checking engine, try to find credible sources also reporting on the same issue. T is for Trace. Find where the claim or news came from originally. Credible media outlets can also fall into a trap.
My own take on this is instead of sharing then thinking, just don’t think and don’t share. Only share when you have had time to verify, when you feel confident in the post or news item, and when you can add something, even if it’s only a personal comment or opinion. We all know that a piece of stupid fake news can be a fun item to one friend, but be destructive and destabilising to another friend.
Don’t think, don’t share, and then verify, think, edit, comment, and share selectively.
AI's 'insatiable' electricity demand

In an article entitled “AI’s ‘insatiable’ electricity demand could slow its growth — a lot, Arm exec says, “data centers powering AI chatbots already account for 2% of global electricity consumption“. It would appear that ChatGPT requires 15 times more energy than a traditional web search. A separate report estimates that energy consumption from hardware in data centres will more than double in the years ahead, according to Reuters, from 21 gigawatts in 2023 to more than 50 gigawatts in 2030.
The article also mentioned that there were already 9,000-11,000 cloud data centres across the globe, and in that for 2024 it was estimated that they would consume 46 terawatt-hours, three times more than 2023.
“Electricity grids creak as AI demands soar” is another article on how AI is pushing the demand for electricity.
Generative AI systems create content (answers) from scratch and use around 33 times more energy than machines running task-specific software. In 2022, data centres consumed 460 terawatt hours of electricity, and this will double over the next four years. Data centres could be using a total of 1,000 terawatts hours annually by 2026.
Interesting how the figures are inconsistent between the two articles.
Sweden has long opposed nuclear weapons – but it once tried to build them

This article noted that after World War Two Sweden embarked on a plan to build its own atomic bomb. They only stopped planning for the production of nuclear weapons in 1966, but carried on limited research into the 1970s.
They signed the Non-Proliferation Treaty (NPT) in 1968, and joined the EU on 13 November 1994.
A library on the moon?

The article “There’s a library on the moon now. It might last billions of years” tells us that 30 million pages, 25,000 songs and a whole bunch of art was left on the Moon by the Galactic Legacy Archive. Sunlight and gamma rays which bombard the Moon’s surface would break down paper, so the archive is etched in nickel, on thin layers so tiny that you need a microscope to read them. For the music and images there is a nickel-etched primer describing the digital encoding used.
The cloud under the sea
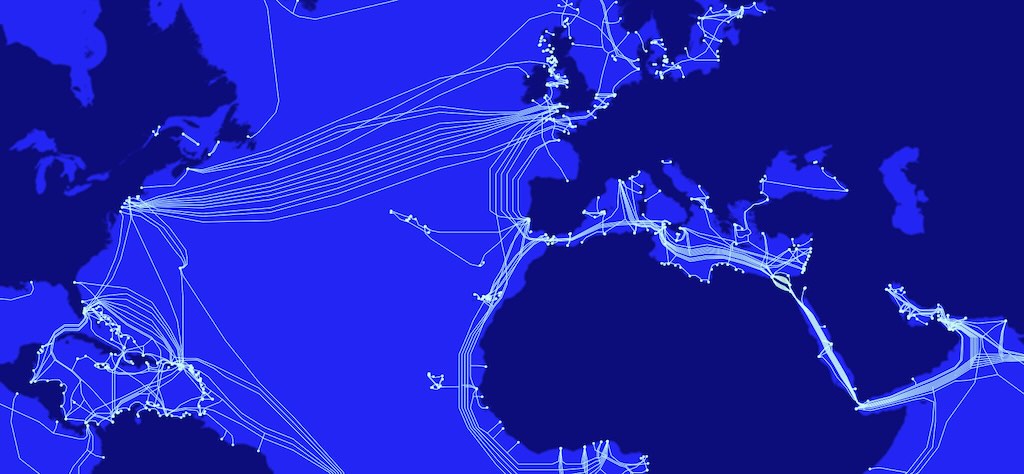
“The Cloud Under the Sea” is a very extensive article, with a really impressive set of graphics, etc., about cable ships that lay and maintain undersea communication cables, the backbone of the Internet.
I would be doing the article a disservice if I tried to summarise it, it’s worth more than that. And as a primer check out Wikipedia on “Submarine communication cable” and the “Cable layer“.
The Contested World of Classifying Life on Earth

This article is about taxonomy, and specifically about the fact that there exists no single, unified list of all the species on Earth.
This appears to be a bit surprising, as are the heated discussions about how to come up with a single ranking list. Some people consider taxonomy as the most fundamental biological science because it reflects how humans think about and structure the world. A “common shared understanding” sounds like a good idea, but some expert groups wrote that is was “not only unnecessary and counterproductive, but also a threat to scientific freedom”.
This is not an article that will interest everyone, but I just found the whole context both surprising and disappointing.
Identity theft
This article “Man pleads guilty to stealing former coworker’s identity for 30 years“, described how someone used a coworkers identity to commit crimes and rack up debt. In addition the victim was incarcerated after the thief accused the victim of identity theft and the police failed to detect who was who.