TV quiz programs occasionally include questions about the meaning of parts-of-speech in English, e.g. verbs, nouns, adjectives, adverbs, determiners (including articles), prepositions (and postpositions), and conjunctions, to which we can add interjection, clauses, sentences and even numerals.
This post will focus on the English language, which is in fact a West Germanic language (along with Dutch and German). The other two Germanic languages were the North Germanic languages (Nordic languages) and the extinct East Germanic languages. These languages are seen as deriving from a Proto-Germanic language, one of the early Indo-European languages (which included also the Romance languages, etc.).
English and England are named after the Angles, one of the ancient Germanic peoples who migrated into Great Britain in ca. 500 AD. It is thought that they took the name from the Anglia Peninsula in modern-day Germany. The earliest forms of English, a group of West Germanic (Ingvaeonic) dialects brought to Great Britain by Anglo-Saxon settlers in the 5th century, are collectively called Old English.
Middle English began in the late 11th century with the Norman conquest of England (1066 AD), and this was a period in which English was influenced by Old French, in particular through its Old Norman dialect.
Early Modern English began in the late 15th century with the introduction of the printing press to London, the printing of the King James Bible (1611), and the start of the Great Vowel Shift (1400-1700).
Modern English has been spreading around the world since the 17th century thanks to the worldwide influence of the British Empire and the United States.
Below we have Old English (1), Middle English (2), Early Modern English (3), and Modern English (4).

What about those quiz questions ...
Which came first syllables or letters? Answer – The earliest syllables date from ca. 2800 BC, and it looks like syllables derived from pictograms, so they pre-date letters. Remember syllables are speech sounds, and are usually made up of a vowel mixed with one or more consonants.
Which is the longest word that appears in a play by William Shakespeare (English, 1564-1616)? Answer – Honorificabilitudinitatibus (27 letters) in “Love’s Labour’s Lost“, and it means “the state of being able to achieve honours“. It is also the longest word in the English language featuring only alternating consonants and vowels.
How can you tell the difference between a vowel and a consonant? Answer – It’s the breathing, consonants stop you breathing, whereas vowels don’t. Vowels are spoken without any blockage in the airflow, whereas, for example, with a ‘b‘ you must fully close your lips and then release the airflow. This means that a vowel is made with the mouth fairly open, whereas the consonant is a sound made with the mouth fairly closed. The ‘y‘ is often called a semi-vowel because it works as a consonant in ‘yell‘ and ‘young‘, but as a vowel in ‘myth‘ and ‘hymn‘.
What are the letters you cannot say without your lips touching? Answer – These are the so-called bilabial plosive sounds which require the lips to touch, so B, M, P and W. A ‘stop consonant‘ is called ‘plosive’, where the vocal tract is blocked so that all airflow ceases (the blocking can be made with the lips or the tongue).
What is the name of the little dot on ‘i’ and ‘j’? Answer – A tittle.
Which English word has the most definitions? Answer – ‘Set’, according to one report has 464 different definitions.
How many English words can you make from the word ‘therein’ without change the word order? Answer – 10, with the, there, he, in, rein, her, here, ere, therein, herein.
Which English word contains three consecutive double letters? Answer – Bookkeeper or bookkeeping.
What punctuation mark ends an imperative sentence? Answer – The imperative sentence is a grammatical mood that suggests a command or request, and thus best goes with a ‘full stop‘ or ‘exclamation mark‘. Examples would be Stop. Give Way. Do Not Enter. or “Put the gun down!” and “Don’t be late!“.
What does an adjective modify? Answer – Nouns and pronouns. Adjectives modify nouns, and can precede or follow a noun, e.g. “my happy kids” or “my kids are happy“.
‘Euouae‘ is the longest English word containing only vowels, but what does it mean? Answer – It is an abbreviation derived from the vowels in “saeculorum Amen” of Gloria Patri. ‘Euouae‘ is also the longest word with the most consecutive vowels (6), but there are quite a number of English words containing five consecutive vowels, e.g. queueing.
What is the longest English word that contains only one vowel? Answer – Strengths. However there are longer words that contain repetitions of only one vowel, e.g. Chrononhotonthologos, which today means an ineffective authoritarian blusterer (we see these blusterers on the television everyday). The shortest English words containing only vowels are ‘I‘ and ‘a‘. ‘aa‘ is one spelling for ‘A’ā, a type of lava flow, and there are quite a number of different definitions of ‘oo‘.
What is the longest one–syllable word in English? Answer – Screeched is the most frequently mentioned, but there are other words also with nine letters (e.g. scratched, stretched, …). There are of course 1,000’s of one-syllable English words.
What is the longest English word that has all its letters in alphabetical order? Answer – Almost.
What is the longest English word that can be spelled without repeating any letters? Answer – Uncopyrightable.
What is the shortest English word that contains all five vowels exactly once? Answer – Eunoia, which is a term in rhetoric meaning “well mind; beautiful thinking“.
Which was the last letter to be added to our modern 26-letter English alphabet? Answer – It would appear that ‘j’ was the last letter added to the English alphabet. It was initially used to the end of the Roman Numeral for 13, with xiij and it was Gian Giorgio Trissino (Italian, 1478-1550) who introduced a consonantal ‘j‘ in 1524. From Italian it spread to the other languages, only for it to be later abandoned in contemporary Italian.
Some simple definitions
Letter is a unit of a writing system, and contemporary English has 26 letters. Letters combine to form words. Letters can be either consonants or vowels.
In fact letters are a type of grapheme, the smallest functional unit of a writing system. A grapheme is an abstract notion for the smallest unit of writing, but in practice it needs to be seen in a specific written form, such as a typeface. So we should consider a grapheme as a minimal unit of writing that is distinctive and corresponds to a linguistic unit (e.g. something that is spoken). As an example ‘sh‘ corresponds to a specific sound (a phoneme) in a word such as ‘shake‘ and therefore it is represented by a grapheme in a writing system. So a grapheme is an analog of a phoneme, it’s a way to represent spoken language with symbols (written language).
A writing system try’s to keep the same semantic structures as in speech, and uses symbols to represent a language’s phonology (the study of spoken sounds) and morphology (the study of words).
We now need to translate a grapheme into a set of coherent signs in a text in a writing–reading system. Those elemental signs are called glyphs, and collectively they allow us to create an alphabet, to spell out words, to build sentences, and so on.
Today we see glyphs as letters in printed text, and a collection of glyphs (letters, numbers, punctuation marks, etc.) that form a typeface. There are lots of different typefaces (see list), and each letter can be regular, bold, italic, etc. Typography involves arranging type to make written language legible and readable.
A grapheme is an abstract notion for the smallest unit of writing, a minimal unit of writing that is distinctive (contrasting) and corresponds to a linguistic unit. Phonemes are specific spoken sounds that make up a spoken word, and graphemes represents those sounds in the writing of the same word. So graphemes can be just one letter (e.g. b, p, s,…) or several letters (e.g. ch, ff, th, -ck, -igh, -ough). As an example, ea, as written in leaf, is a grapheme, and represents the phoneme /ee/.
A digraph is a two-letter grapheme that represents just one sound, and a trigraph is a three-letter grapheme that still just represent one sound.
So glyphs are the ‘surface form’ of graphemes, a concrete representation of a symbol. Keeping it simple, in English graphemes are just the letters (and the other stuff you see on your keyboard). A glyph is a letter (say ‘g‘) irrespective of the font, bold, lowercase, capital, italics, etc. The grapheme is the written ‘g‘, and the variations on ‘g‘ (e.g. G, g, 𝑔, …) are allographs.
Glyphs are not just letters, they can be hieroglyphs or pictograms, or any other visual representation of verbal communication, and collectively they make up a script or writing system. The word hieroglyph comes from the Greek and broadly speaking means ‘scared carving/engraving’ (hierós-glyphō).
Diacritics are signs in the form of a glyph added to a letter or basic glyph, e.g. the bit on top of é, à, ü, â, etc. They often change the sound of the letter when spoken, but not always (e.g. là (there) and la (the) are pronounced the same in French). English is the only major modern European language requiring no diacritics for native words.
Phonemes are the basic unit of sounds (phones) in a spoken language, in a sense they are the way we distinguish one word from another. The basic unit of speech sound is the phone, and it is independent of its importance to the meaning of the words (so they are absolute sounds and not specific to any language). Phones are generally associated with vowels or consonants. Whereas phonemes are speech sounds that if swapped around change one word to another (so they are dependent upon the language used). For example, the ‘p‘ in pun and in spun are different, and involve slightly different sounds. But it’s not possible to change the different ‘p‘ sounds around and get different words. So the two ‘p‘ sounds are different phones, but not different phonemes in English. However, if we look at kid and kit, each ends with two different phonemes, which if swapped one for the other changes the words in English. Note that it’s written “in English“, because in another language changing the ‘p‘ sounds actually can produce two different words, so the sounds are two different phonemes in that difference language. In this sense it’s the phonemes, rather than phones, that are reflected in the writing system of a particular language.
In modern-day phonetic speech analysis the phone is the basic speech segment or unit. We noted that with the ‘p’ in pin and spin, the ‘p’ sounds were different phones of the same phoneme, so they are called allophones.
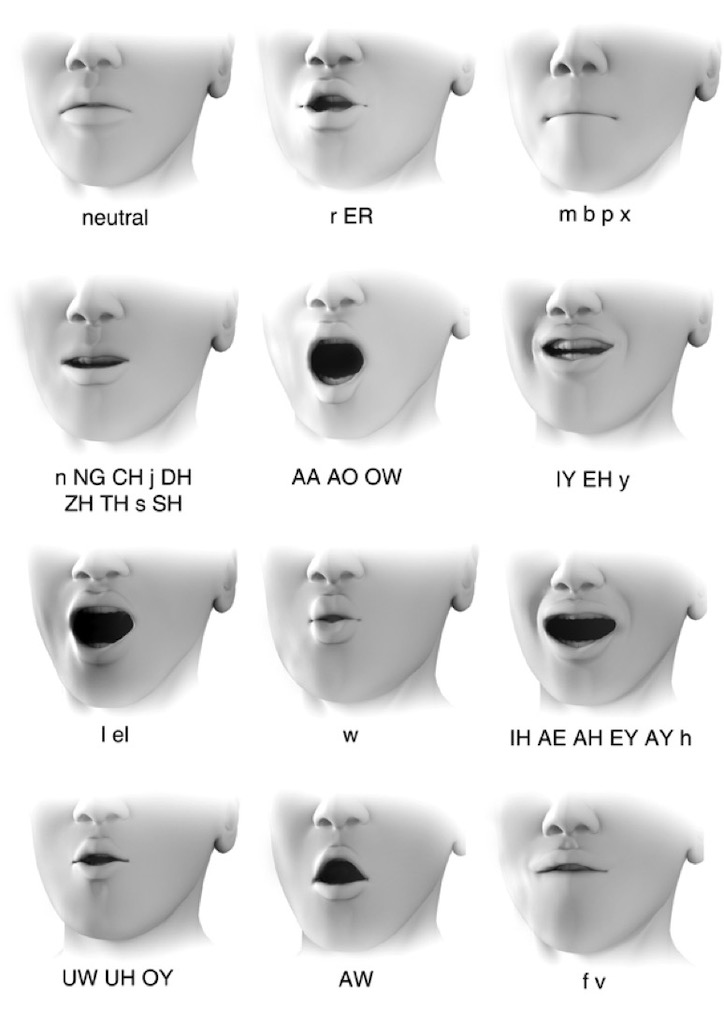
Above we have just one of the many charts describing the relationship between lip or mouth movements and phonemes. The topics of speech perception, speech recognition, speaker recognition, and speech synthesis are important on-going research topics in areas such as speech translation. More recently lip-sync has become increasingly important for the creation of believable virtual agents, avatars, chatbots, etc. You need to first generate a voice track, then break it down into phonemes, and then synchronise and animate a face to the dialogue. The voice track is usually generated by a text-to-speech engine where the input text is converted into phonemes and is ‘marked up’ to describe pitch, volume, speech-rate, etc. (this is both language specific, and accent specific). Alongside phonemes as basic acoustic units of speech, there are visemes which are the basic visual units of speech. Visemes represent the lip/mouth pose, however there is not a one-to-one relationship between phonemes and visemes. Generally about 22 visemes are sufficient to represent the 44 phonemes in English, and these 22 visemes can be reduced to the 12 mouth shapes seen above.
What is an alphabet?
Alphabet is a standard set of basic symbols or graphemes (or letters in plain English). English uses the basic ordering of the Latin alphabet (a b c … j k l … x y z), with upper- and lower-case forms (A.a B.b … Z.z). These basic symbols or graphemes represent the sounds in the spoken languages, and the unit of sounds are called phonemes.
According to Wikipedia the most frequently occurring letters in the English language are ‘e’ (11.2%), ‘t’ (9.4%), ‘a’ (8.5%), ‘r’ (7.6%), and ‘i’ (7.5%). ‘z’ is the least frequently occurring letter in the English language, followed by ‘q’, ‘x’, and ‘j’. Another Wikipedia article has a different offering with e-t-a-o-i-n-s-h-r, and not e-t-a-r-i (‘z’ is always last). The problem is that there are different ways of counting. You can just count root words, or you can use all the words in a dictionary or encyclopaedia, or you can analyse text corpora (newspapers, books, etc.), and each will give you different results. However ‘e’ always comes out on top in English.
That first article in Wikipedia told us that ‘t’ followed by ‘a’, ‘o’, ‘i’, and ‘s’, are the most frequently occurring first letters of English words (‘z’ and ‘x’ are equal last). The same article also told us that ‘e’ is still on top in French, German, Spanish, Italian (only just), Swedish, Dutch and Danish, but ‘a’ is on top in Portuguese, Turkish, Polish, Finnish, and Czech. If you are looking for a trick-trivia question, then ‘e’ is just beaten for top place by the ‘space’, and the collection of all the other non-alphabetic characters would sit in 4th place.
Initially the Romans used an alphabet of 23 letters, with ‘j‘, ‘u‘, and ‘w‘ missing (and ‘h’, ‘k’ and ‘z’ rarely used). The letter ‘w‘ started out as ‘uu’ or ‘vv’, but it only gained in popularity in the 13th century. and it would only gain its distinct ‘w‘ in the 14th century. The letter ‘u‘ separated from ‘v‘ and they became distinct letters from 1386, but printers only adopted the ‘u‘ in the 17th century. It would appear that ‘j‘ was the last letter added to the English alphabet. It was initially used on the end of the Roman Numeral for 13, with xiij and it was Gian Giorgio Trissino (Italian, 1478-1550) who introduced a consonantal ‘j‘ in 1524. From Italian it spread to the other languages, only for it to be later abandoned in contemporary Italian.
No one really knows why we have English letters in the order we have (see abecedarium), but it would appear that the basic order has existed for at least the last 2,500 years.
In French é, à, ô … are not considered additional letters, however ñ is considered a separate letter in Spanish (but á, é, … are not). So whilst Spain has 27 letters in its alphabet, Italy only has 21 letters in its alphabet (j, k, y, x and y are technically not part of the Italian alphabet, and appear only in loanwords). Sweden has 29 letters in the alphabet, by added å, ä, and ö. Finland uses the same alphabet as Sweden, even if it does not use å in its native words (also b, c, f, q, w are used predominantly in loanwords and foreign proper names). The Czech alphabet consists of 42 letters.
In addition to the alphabet there are punctuation marks that are aids to understanding and reading written texts. Different punctuation can change dramatically the meaning of a sentence. The key evolution of punctuation marks was with the copying and printing of the Bible. Because it was to be read aloud, there was a need to provide visual clues to render the text more intelligible (e.g. word separation appeared in ca. 800 AD). It was with the Norman Conquest that a more ‘modern’ system of punctuation was introduced, however with the arrival of printing (ca. 1440) an even newer standard was introduced. That standard was then simplified with the introduction of telegraphy (1840’s) and typewriters (1870’s). English punctuation tries to make texts easy to read aloud, whilst keeping the sentence structure.
All spoken languages have phonemes for at least two types of speech sounds or linguistic units, namely vowels and consonants that can be combined to form syllables.
Vowels refer to 5 letters of the alphabet, a, e, i, o and u. Without becoming too technical, these speech sounds are produced with an open vocal tract, so no significant build-up of air pressure above the glottis.
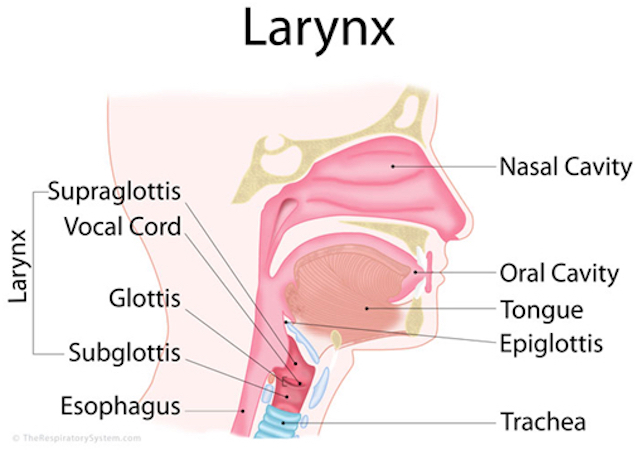
The laryngeal cavity, the pharynx, the oral cavity, and the nasal cavity make up the vocal tract, which collectively are used by mammals to produce sounds. The larynx is called the voice box, and one of its tasks is to produce sounds. The larynx houses the glottis which is the sound apparatus, and consists of the vocal cords (often also called the vocal folds) and the opening between them. So the idea is that the lungs build up pressure below the glottis (initiation), and the vocal folds then vibrate making a sound (phonation) with a particular pitch and volume. The voice is then formed by shaping that sound in the oral and nasal cavities (oro-nasal process and articulation). This combination means that in theory we can produce a wide variety of different unique sounds, however in English we only produce 44 different sounds (it varies from 11 to 141 depending upon the language).
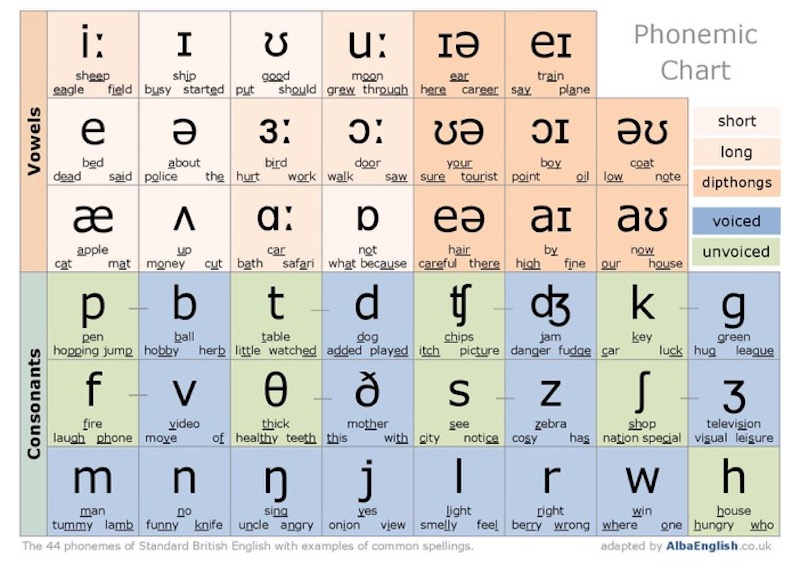
Above we can see the 44 different sounds used in spoken English. Of course, for most people, we must think before we speak, so it all starts in the brain. What we have rapidly described above is the physical production of sounds.
Consonants refer to the 21 letters of the alphabet, which are speech sounds with a complete or partial closure of the vocal tract. In fact English has more than 21 consonants sounds, so digraphs (like sh in shop) are used to extend the alphabet.
A syllable is a sequence of speech sounds (phones), usually made up of a vowel and an optional consonant. In this sense they are the ‘building blocks’ of spoken words, and a word such as ‘ignite‘ will be composed of two syllables, namely ig and nite. Historical it would appear that syllables derived from pictograms and pre-date letters. Some words are mono-syllables (e.g. dog), and others have two or more syllables (poly-syllable).
The vowel is the sound that is formed at the peak (nucleus) of a syllable and is the most sonorous part, whereas the consonant provides the less sonorous part at the onset (beginning) and coda (end).
Always good to remember that every syllable has one vowel sound, and that the number of vowel sounds in a word equals the number of syllables. Also one syllable words cannot be divided up.
What is a morpheme?
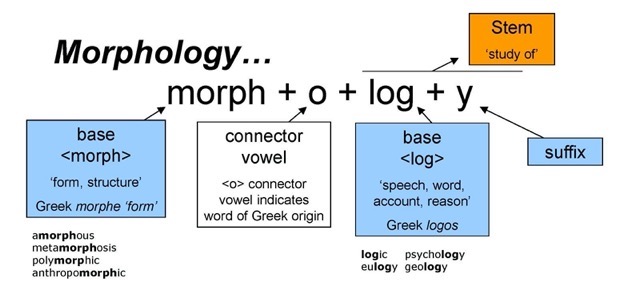
A morpheme, according to Wikipedia, is the smallest meaningful unit in a language. The emphases is on meaningful. Morphemes may or may not stand alone. When a morpheme stands alone it is a root, meaning that it has a meaning on its own. A morpheme might depend upon another morpheme to express a specific idea, e.g. cat is a morpheme, and it can be associated with an affix (such as -s) which is also a morpheme. When the two morphemes, cat and -s, are joined together they form a new word, e.g. cats. So ‘free morphemes‘ function as independent words, whereas ‘bound morphemes‘ appear as parts of words. Most of these ‘bound morphemes‘ are prefixes or suffixes. Suffixes, such as -s and -ed, are so-called ‘functional morphemes‘ because they have a grammatical function. Other morphemes, such as fast or sad, express a concrete meaning, and are usually nouns, adjectives, verbs, or adverbs. ‘Functional morphemes‘ are usually propositions, pronouns, determiners or conjunctions.
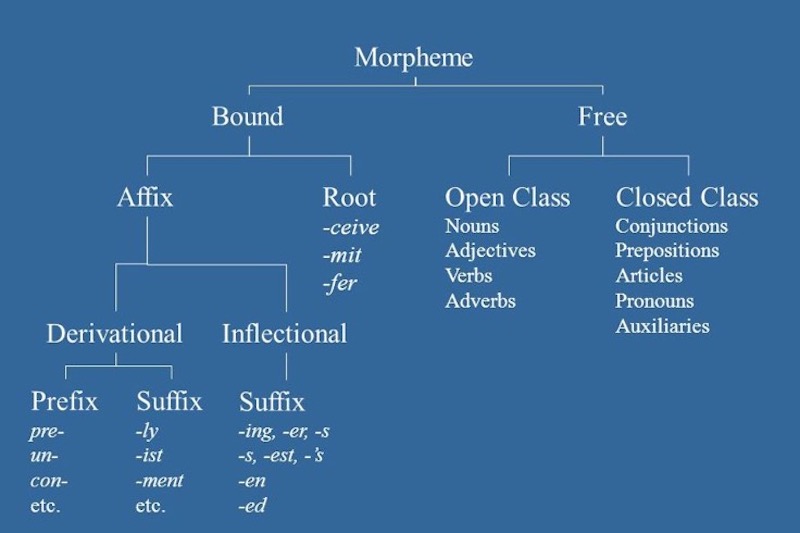
To delve deeper in to the components that make up words, we must introduce the topic of morphology, the study of how words are constructed from their component parts, or morphemes, and the relationship between words in the same language. As mentioned above, morphemes are the smallest meaningful units in a language, or the smallest meaningful combinations of letters. Words can be broken down into roots, stems, and affixes. A root is a morpheme that forms the basis of a word, e.g. it carries a meaning, that can be quite precise or quite vague and general. A word has only a single root morpheme. Cat is a morpheme, and it is a root because it has a meaning all on its own. Some roots can stand alone, but many require affixes. Affixes refer to bits of words that come at the beginning (prefix), in the middle (infix), or at the end (suffix).
As an example, let’s take the noun ‘nation‘, which comes from the Old French word nacion, which in turn originated for the Latin word natio meaning ‘birth’. Nation is a synonym for state or country, and by adding the adjectival suffix ‘-al‘ we obtain the adjective ‘national’. Now we can use the verb-forming suffix ‘-ize‘ to form the verb ‘nationalize‘. Historically the suffix would have been ‘-ize‘, however due to the French influence in the 19th century the spelling ‘nationalise‘ is also valid. We can now create a new verb by adding a prefix ‘de-‘ to reverse the sense of the word with ‘denationalise‘. And we can then use the suffix -ation, representing a process, to obtain the new noun ‘denationalisation‘ meaning privatisation. And you can alway add the plural making suffix ‘-s‘, to make ‘denationalisations’.
An additional point worth noting is that ‘nation‘ is a root, whereas new words formed from that root are stems, namely nation-al, national-ise, and de-nationalise, etc.
Two different types of affixes are possible, inflectional and derivational.
Both inflectional and derivational affixes modify the root word, but:-
-
Inflectional affixes do not change the meaning or class of the root word, e.g. read to read-ing
-
Derivational affixes change the class of the root word and creates a new word which requires a new definition, e.g. magic to magic-ian.
Inflections are affixes used to derive different grammatical categories, namely:-
-
Tense, the placing of a verb in a time frame, which can take values such as present and past (suffix -ed)
-
Number, with values such as singular, plural (suffix -s), and sometimes dual, or trial (i.e. 3)
-
Gender, with values such as masculine, feminine and neuter
-
Noun classes, which are more general than just gender, and include additional classes such animate vs. inanimate, human vs. non-human, human vs. animal, strong vs. weak, count noun vs. mass noun.
This last class is interesting because a count noun is modified by a numeral, whereas a mass noun is not, e.g. you have a chair and chairs, but you do not have furnitures because furniture is a mass noun.
Inflecting a noun, pronoun or adjective is called a declension, i.e. indicates number, case, gender, etc. Wikipedia tells us that English has largely lost its inflected case system although personal pronouns still have three cases, which are simplified forms of the nominative, accusative and genitive cases. They are used with personal pronouns: subjective case (I, you, he, she, it, we, they, who, whoever), objective case (me, you, him, her, it, us, them, whom, whomever) and possessive case (my, mine, your, yours, his, her, hers, its, our, ours, their, theirs, whose, whosoever).
Below I found a simplified description of the declension.
Nominative – Subject – The thing doing the action of the verb
Examples:- “He senses a problem”, “They followed the signs to the mall”, “The girls are swimming”
Genitive – Dependent – Ownership, like with an ‘s
Examples:- “Our citizens are proud of our country”, “The man’s dog has just eaten our hat”
Dative – Indirect Object – A thing that is receiving something, like “to“
Examples:- “I am building a house for you“, “We gave a bone to our dog“, “We gave our dog a bone”
Accusative – Direct Object – The thing that the verb is being done to
Examples:- “The dog ate our dinner” (ate what?), “The leopard chased him for an hour” (chased who?)
Ablative – Prepositional Clause – with, of, from, … used to express motion away from something
Examples:- “The victim went with us to see the doctor”, “I got bored with the guy”
Vocative – Speaking – not really used in English, replaced by the objective case
Examples:- “You there, are you O.K.?”, “Marcus, stay in the house”
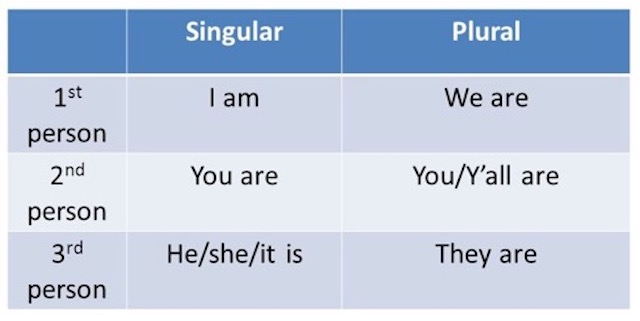
Inflecting a verb is called a conjugation. Frankly the Wikipedia article looks daunting, however, fortunately English is simpler than most other languages.
As an example, the conjugation of the verb ‘to be‘ is…
Derivation is the process of forming a new word from an existing word, often by adding a prefix or suffix. So an inflection changes the core meaning, but a derivation does not. However a derivation does change the grammatical category, e.g. en- and gulf produces engulf, and with -er, read becomes reader. Derivations are usually easy to spot because the basic meaning stays the same, e.g. write to writer, slow to slowness, red to reddish, etc.
I came across an interesting explanation and some examples of the difference between a root, stem, and affix. The first example was for the root ‘acri‘, which means to make sour or bitter. To make a recognisable word we can add the derivational suffix ‘-mony‘, making the word ‘acrimony‘, which is a stem. Then the plural ‘acrimonies’ can be created by adding the suffix ‘-ies‘, a plural form for nouns ending in the consonant ‘-y’. Or ‘acrimonious‘ can be created with the suffix ‘-ious‘ which denotes the possession or presence of a quality. What we see is that the root ‘acri‘ carries the basic meaning, the stem ‘acrimony‘ is the smallest part that can take an inflectional affix. And we can see immediately that it is the stems that are usually found in dictionaries.
Another example is the root ‘-fer’, to which derivational prefixes can be added to create the stems ‘refer’, ‘differ’, ‘prefer’, …, and to these, inflectional suffixes can now be added to create ‘referred’, ‘differing’, ‘prefers’, … Again it’s the stems we will find in a dictionary.
The above discussion on morphology has been substantially simplified, but don’t be surprise if most English adults are not aware of these details. In one presentation, they said that today, student English competency was so poor that it is no longer realistic to suppose that they can learn and understand the theory behind declension and conjugation. Remember the average American adult reading age is equivalent to a 12 year old, and the average reading age of the UK population is now that normally expected of a 9 year old. Don’t smile, the worst in Europe are France, Italy and Spain where more than 20% of adults can’t read and write properly (the ‘best’ is Finland with ‘only’ 11%).
What is a word?
Word is the smallest thing that can be spoken that has a practical meaning, although some words may have multiple meanings (polysemy). This is the same as saying that a word is the smallest group of phonemes (sound units) that can be uttered in isolation and make sense to the listener. The spoken word also corresponds to a sequence of letters (graphemes) in the writing system. Words are combined to form elements of a language, i.e. phrases, clauses and sentences. Although word separators (e.g. spaces) are said to be quite a modern invention, they are used to indicate where one word stops and another starts. However, there are compound expressions (e.g. ice cream) where the true sense is found only with more than one word with a space, so the definition of word is not so simple.
What is a phrase?
A phrase (expression) is a group of words that can have either a special idiomatic meaning or a non-literal meaning. However, a phrase can have a noun or a verb, but it does not contain a subject with a verb. Often we think of phrases as idiomatic expressions such as “kick the bucket“, but they don’t have to have a special meaning, however it must function as a grammatical unit like “very happy” or “for twenty days”. So “kick the bucket” and “very happy” are phrases because we don’t know about the subject, e.g. who is “very happy” or is going to “kick the bucket“?
In addition there are a number of different types of phrases that depend upon the syntactic category of the key word in the phrase, namely:-
-
Adverbial phrase – in this example sentence “I’ll go to bed“, it can acquire a modifier adverbial phrase to make “I’ll go to bed in an hour“
-
Adjective phrase – is a phrase that modifies an adjective which is already modifying a noun, so the adjective ‘happy‘ in the phrase “very happy” becomes either “a very happy man” or “The man is very happy“
-
Noun phrase – phrases with a noun occur frequently, such as “Almost every sentence contains at least one noun phrase“, actually contains two noun phrases “Almost every sentence” and “at least one noun phrase“
-
Preposition phrase – English is a ‘head-initial‘ language (pre-positional), and it has a wide variety of words to express spatial and temporal relations normally built around a noun, e.g. “to his desk“, “in the kitchen“, “with chopsticks“, “on the top floor“, “inside the car“, “up the stairs”
-
Verb phrase – are composed of a verb and its object, complement and modifiers, e.g. “has finished the work“, “try that“, “has given“
-
Subordinate phrase – with words like after, as, as long as, because, before, every time, since, so, that, until, when, where, while.
What is a clause?
A clause is part of a sentence that does contain a subject with a verb. A two word clause can also be a complete sentence because it makes sense (a phrase will not make complete sense and can’t be a sentence on its own). Sentences can contain more than one clause. There are two basic types of clauses, the independent clause (which express a complete thought and can stand as a simple sentence), and the dependent clause (a subordinate clause which provides additional information but can’t stand alone as a sentence). Unfortunately, there are three types of dependent clauses, and each has a variety of different sub-classes which can make things very complicated. Keeping it as simple as possible:-
-
Content (or noun) clauses – provides content or comments upon the independent clause
-
Relative (adjectival) clauses – are dependent clauses that modify a noun or noun phrase
-
Adverbial clauses – are dependent clauses that function as an adverb in that the entire clause modifies a verb.
Examples of a phrase are – “on the wall”, “in the kitchen”, “over the horizon”, after dinner”, “waiting for the rain to stop”, “best friend”, “with the blue shirt”, “very quickly”
Examples of a independent clause are – “I run”, “I waited”, “He told her”, The dog barked at him”, “She laughs”
Remember, to be a clause it must have both a subject and a verb, and the phrases above don’t contain both. Independent clauses express a complete thought and can be simple sentences, whereas dependent clauses can’t stand alone. Independent clauses “He went out to dinner” and “He didn’t enjoy the meal” can also be joined together using a conjunction, forming “He went out to dinner, but didn’t enjoy the meal”
Examples of a dependent clause are – “When the man broke into the house”, “Because I am feeling well”, “Whatever they decide”, “Since it fell on the floor”, “Because she smiled at him”
A dependent clause with an independent clause can make a sentence “When the man broke into the house, the dog barked at him”
Example of a content clause, “she was smart” because it adds content/context to “He told her (that) she was smart”
Example of a content clause that can be added to an independent clause. The independent clause “He decided to proceed” acquires an addition content clause and becomes “Convinced, (that) he could manage it without help, he decided to proceed”.
Example of a relative clause that can be added as a dependent clause. “I saw yesterday” is a clause because it contains a subject and a verb, but it’s not a sentence in itself. However we can use that information to give additional meaning to the noun ‘man’ in the independent clause “The man went home” . The result is “The man I saw yesterday went home”
Example of an adverbial clause that can be added as a dependent clause. “Peter, the drama teacher, met with Mary” is an independent clause. We can add an adverbial clause, obtaining “Peter, the drama teacher, met with Mary after she came to the class”. The entire adverbial clause modifies the verb ‘met’, and ‘after’ is a subordinating conjunction, which is a kind of ‘trigger word‘ that joins an independent clause and a dependent clause.
What is a sentence?
A sentence is a unit with words that are grammatically linked.
Examples:-
The sentence “I looked everywhere but the cat was gone” contains two clauses, “I looked everywhere” and “cat was gone”.
The sentence “He is playing in the field” contains a clause “He is playing” (subject+verb) and a phrase “in the field”.
What is a grammar?
A grammar is a set of structural rules on how words, clauses, phrases are composed into meaningful sentences. According to Wikipedia, grammar appears to encapsulate a number of complex technical areas. Fortunately a child learning their native language does not consciously study these topics, but learns by hearing others speak. These technical domains include:-
-
Phonetics – the study of the physical properties of speech sound production and speech perception, including acoustic phonetics and articulatory phonetics
-
Phonology – the study of sounds as abstract elements in the speaker’s mind that distinguish meaning (phonemes)
-
Morphology – the study of morphemes, or the internal structures of words and how they can be modified
-
Syntax – the study of how internal structures of words combine to form grammatical phrases and sentences
-
Semantics – the study of the meaning of words (lexical semantics) and fixed word combinations (phraseology), and how these combine to form the meanings of sentences as well as manage and resolve ambiguity
-
Pragmatics – the study of how utterances are used in communicative acts, and the role played by situational context and non-linguistic meaning
-
Discourse analysis – the analysis of language use in texts (spoken, written, or signed)
-
Stylistics – the study of linguistic factors (rhetoric, diction, stress) that place a discourse in context
-
Semiotics – the study of signs and sign processes (semiosis), and including analogy, metaphor, metonymy, symbolism, signification, and communication.
Grammar, morphology and syntax
It is worth considering again the exact definitions of grammar, morphology and syntax, because people are often confused by the terminology.
Let’s first look at the difference between morphology and syntax. We have written that morphology is the study of the structure of words as formed from their component parts (morphemes). Syntax is about the internal structure of expressions formed by using words, i.e. the rules to order words into meaningful clauses, phrases and sentences. One important feature of syntax is ‘agreement‘ which is how words change (or ‘agree’) depending on the other words in the clauses, phrases and sentences. Technically this is called matching the grammatical category across the different constituents (words or groups of words) of a sentence. Someone wrote that morphology is “what goes on inside words” and syntax is “what goes where in a sentence”.
Grammar is a more general term, includes morphology and syntax, and dictates the structural rules for the correct or standard usage of a specific language. Syntax is often defined as the rules, principles and processes that govern the word order of expressions and sentences in any language. Some definitions of grammar also include orthography (writing conventions) and accidence (inflection) along with morphology and syntax.
One interesting perspective is that morphology is about the internal economy of words, i.e. the most efficient way to put together the component parts (morphemes) into meaningful words (e.g. the way to use ‘book’, ‘keep’, ‘-er’, and ‘-s’ to create the unique and useful word ‘bookkeepers’). Syntax is about the external economy of words i.e. the most efficient way to order words into meaningful clauses, phrases and sentences. English being an analytic (uninflected) language, the main focus is on efficient syntax.
So syntax is descriptive and involves observing the rules of word order, whereas grammar sets the prescriptive rules of language that morphology and syntax must respect in order to work together.
Syntax, for a given language, is all about the rules for ordering words into meaningful sentences. In its simplest form it’s about correctly arranging a subject, a verb, and an object, e.g. “I washed the car”. Avoiding a discussion on different theories, we will focus on usage, the way language is written and spoken in everyday life. So this means grammar (rules), syntax (word order) and the style and word choices of writers and speakers (diction).
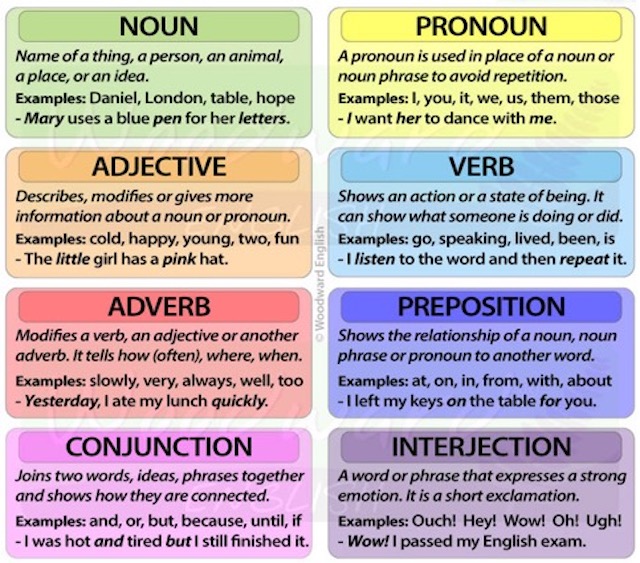
Syntactic categories, word classes, parts of speech, lexical items, don’t all mean the exact same thing, but we will start with common parts of speech in English.
Noun – comes from the Latin meaning name. So nouns are the names of creatures, objects, places, actions, qualities, ideas, etc., and nouns can be both subjects (e.g. “John is an idiot“) and objects (e.g. “He has a dog“). There exist proper nouns (e.g. John, London), common nouns (e.g. person, city), count nouns (e.g. chair-chairs, furniture-furniture), mass nouns (e.g. water, sugar, wood, furniture), collective nouns (e.g. group, youth, coin, committee, and all the collective names for animals), physical entities (anything that occupies physical space), and abstract objects (e.g. justice, humanity, game). In addition there is a process called nominalisation where a process or verb can also become a noun (e.g. poor as in the poor, powerful as in the powerful, carelessness for those who are careless).
Verb – comes from the Latin meaning word. They convey an action (bring, read, walk, run, learn), an occurrence (happen, become), or a ‘state of being’ (be, exist, stand). At it simplest verbs can be intransitiveor transitive depending upon whether they are associated with a direct object or not. So in “You need to fill in this form” the verb “fill in” is associated with “the form” and is transitive. Whereas the verbs “My dog ran” and “Water evaporates when hot” are intransitive.
Adjectives – are words than modify nouns or noun phrases. There are different forms of adjectives but the idea is simple, e.g. “I took my happy kids for a walk“, “My kids are happy“.
Adverbs – are words or expressions that modify verbs and verbal phrases, e.g. “She sang loudly“, “You are quite right“, “Your seat is there“. A good test is to look to see if it answers a question, how?, in what way?, when?, where?, to what extent?.
In English some words can be adjectives or adverbs depending upon the context, e.g. fast is an adjective in “A fast car”, but is an adverb in “He drove fast“.
Pronouns – are words that can replace a noun. There are quite a variety of subtypes:-
-
Personal Pronouns – are what we encounter often in learning a language, and they are first person (I), second person (you), and third person (he, she, it, they), and it can apply to people, animals and objects.
-
Possessive Pronouns – are about ownership (my, mine, you, yours, his,… ours, theirs)
-
Reflexive Pronouns – end in -self and -selves, as in myself, themselves, …
-
Demonstrative Pronouns – are this, that, these, those
-
Indefinite Pronouns – is a vast collection of very common-day words. For people, no one, nobody, everyone, everybody, someone, somebody, anyone, anybody, and whoever. For things, nothing, everything, something, anything, this, each, another, and other. And for singular and plurals, both, neither, either, others, none, all, some, any and whatever.
-
Relative Pronouns – include which, that, whose, whoever, whomever, who and whom. Relative clauses are formed from relative pronouns, e.g. “I like what you’ve done“.
-
Interrogative words – such as what, which, when, where, who, whom, whose, why, whether and how.
Prepositions (and postpositions) – are usually words expressing spatial or temporal relations (in, on, to, from, with, until, under, towards, before, throughout, atop) and more generally of and for. See List of English Propositions.
Conjunctions – these connect words, clauses and phrases and include for, and, nor, but, or, yet, so, after, once, till, until, when, while … but also include words that work in pairs, e.g. either…or, not only…but, not…but rather, etc., and combinations such as “as long as“, “by the time“, “now that“
In an interesting aside, it is now agreed that sentences can start with conjunctions, e.g. And, But, Yet…
Interjections – are all kinds of spontaneous words or expressions. There is a massive List of English Interjections, so here are just a few, Ouch!, Wow!, Dame!, hey, bye, Okay, Oh!, Huh?, uh, er, um, stop, cool, Shh!, Yuck!, Oops, Hell!, Help! Psst!, Ahem!, brr, tut-tut, Whew, phew, Yeah…
Numerals – are number words, so one, two, … seventy-five, seventy-fifth, …, and words like twice, dozen, third, once, twice, thrice, …, single, double, triple, …, one-by-one, two-by-two, …, in pairs, … A natural number is use for counting and ordering. Cardinal numbers are natural numbers used to express a quantity, and ordinal numbers express the way a collection of objects are placed in a sequence, one after another. Cardinal numbers are one, two, three,…, forty,…, fifty-eight,… whereas ordinal number words are first, second, third,…, as in “fifth of November” (see also ordinal numbering with primary, secondary, tertiary, quaternary or quartary, quinary, sentry, septenary, octonary, nonary, decenary, undenay, duodenary, …). There are also multiplicative number adverbs such as single, double, triple, or once, twice, and thrice, as well as numbers expressed as solitary, double, triple, quadruple, quintuple, sextuple or hextuple, septuple or heptuple, …, or as singular, twofold, threefold, …, hundredfold, … Then there are quantifiers such as all, some, many, few, a lot, every, most, …, and there are expressions such as “one-by-one”, “two-by-two”, or“three each”, etc. And of course there are the so-called “empty numbers”, like umpteen, zillion, …
And we should not forget 0, zero, nought, nil, nothing, null, zilch, zip, duck, blank, … Which of course brings us to other words used for 1, 2, …, such as:-
1, ace, solo, unity, …
2, couple, brace, pair, duce, duo, …
3, trey, trio, hat-trick, …
4, quartet, quad, …
5, quintet, quint, …
6, sextet, half-a-dozen, …
7, septet, …
8, octet, …
9, nonet, …
10, decet, decade, …
11, banker’s dozen, …
12, dozen
13, bakers dozen, …
20, score, …
50, half-century, …
100, century, ton, …
144, gross, …
1000, grand, kilo-,
10,000, a hundred-hundred or myriad.
English ordinal indicators (st, nd, rd, th) derived from first, second, third, and fourth.
The French use 1er or 1re (for premier and première), 2e (deuxième) or 2d (second) or the feminine 2de (seconde), with the plurals being 1ers or 1res (for premiers and premières), 2es (deuxièmes) or 2ds (seconds), or 2des (secondes).
There is a standard for expressing a date, and its 2006-12-31 for 31 December 2006, and 23:59:58 for 23 hours, 59 minutes, and 58 seconds. The most popular way is Day-Month-Year, but Year-Month-Day is also popular (many European countries, including the UK, uses both). The internationally recognised week, starts on Monday. In addition, years can be divided into week numbers.
Article is used with a noun to specify a certain context or definiteness. The definite article is ‘the‘, the indefinite article is ‘a‘ or ‘an‘ (so between the book and a book). There is a proper article that goes with a proper noun, e.g. The Amazon. Then there is the partitive article used with a mass noun, e.g. some water. There exists a negative article, e.g. “No one is in the room“, and even a ‘zero’ article, e.g. “Visitors ended up walking“.
Determiners are words that reference or link one object to another, however they can take a wide variety of forms. Common kinds of determiners include definite and indefinite articles (as seen above with ‘the’ and ‘a’ or ‘an’), demonstratives (this and that), possessive determiners (my and their), cardinal numerals, quantifiers (many, all and no), distributive determiners (each, any), and interrogative determiners (which).
Orthography is a set of conventions for writing, e.g. spelling, hyphenation, capitalisation, word spacing and breaks, emphasis, and punctuation.
Lexicology is the general study of words, how they are composed from morphemes and phonemes, the relationship between word (semantics), and all the elements in the study of the whole lexicon (vocabulary) of a language.
Lexicography is involved with compiling dictionaries, and in using the data to better understand the meanings of words (e.g. lexeme, lemma, …), phrases (phraseology) and sentences.
Syntactic categories, word classes, parts of speech, lexical items, …
Before looking at parts of speech we mentioned that expressions such as syntactic categories, word classes, parts of speech, lexical items, didn’t all mean exactly the same thing. I wrote that because I read it somewhere, but how is it possible to actually define the differences between these different expressions? Well, there are also lots of articles that state that word class is similar to part of speech, which is also variously called grammatical category, lexical category, and syntactic category. Some writers mention (in passing) that these terms are not wholly or universally synonymous, but they don’t go on to explain the differences.
Like ‘being lost in translation’, it’s also easy to get lost in linguistics, as I will demonstrate below…
We have seen above that parts of speech is about the words used in sentences, and I guess this involves categorising words as nouns, verbs, etc. Many sentences can be broken down easily and the nouns, verbs, adjectives, etc. identified and categorised. This might not always be so easy, and David Denison, in “Parts of speech: Solid citizens or slippery customers?“, mentioned the word ‘fist‘ which sounds like it should be a noun, but given that we only make one occasionally, it could be ‘event-like’ and be a verb. Another author noted that ‘look’ is a verb in “She looks good“, but a noun in “She has good looks“.
Some texts suggest that the expression ‘parts of speech‘ is old fashioned, and using word classes is better because they are parts of speech that are defined according to strict linguistic criteria. But it is still not always easy to decide on the boundaries between the classes. One term used is gradience, which I think Wikipedia calls well-formedness. This is about the blurred boundaries between two connecting linguistic elements which create ambiguities usually centred around expressions that are grammatically correct, but native speakers don’t use because they sound odd.
One list of word classes included (in alphabetic order) adjectives, adverbs, articles, conjunctions, interjections, nouns, prepositions, pronouns and verbs.
One credible looking suggestion is that words can be divided into just two classes, ‘form-class words‘ (nouns, verbs, adjectives, adverbs) and ‘structure-class words‘ (the rest, e.g. prepositions, pronouns, …). Some authors prefer to call the first group ‘content words‘, i.e. words with ‘meaning’, and the second group ‘function words‘ i.e. words providing structure or grammar. There are only a few hundred ‘structure-class’ words (e.g. to, the, of, …), and they don’t change very much, whereas the English dictionary is just full of ‘form-class’ words which do change and evolve.
The argument is that in a sentence it is the structure-class words (‘function words‘) which carry grammatical meaning, and ensure that ambiguity is avoided. These words change and evolve very slowly, because any radical change would alter the meaning of what was written or said.
On the other hand, form-class words (‘content words‘) carry the lexical meaning of a sentence. This form-class is open, and is continually acquiring new made-up words or borrowing/modifying existing words from other languages.
So as far as I can see word classes and parts of speech are the same, even if Wikipedia writes “word classes largely correspond to traditional parts of speech“, without defining what ‘largely’ means.
However, Wikipedia does tell us that syntactic categories include both word classes and phrasal categories. And as such, word classes can be called lexical categories, even if some experts prefer to limit the term lexical categories to ‘content words‘, as mentioned above.
As a reminder, word classes (i.e. parts of speech or lexical categories) are nouns, verbs, adjectives, adverbs, pronouns prepositions, conjunctions, interjections and determiners. In addition there are phrasal categories which are combinations of two or three words of different grammatical categories.
As far as I can tell these phrasal categories include adjective phrases, adverbial phrases, noun phrases, preposition phrases, verb phrases, subordinate phrases and apposition phrases. We have not really looked in detail at phrasal categories, so let’s remind ourselves what a phrase is. A phrase is an expression (a group of words) that can have either a special idiomatic meaning or a non-literal meaning. However, a phrase can have a noun or a verb, but it does not contain a subject with a verb. Often we think of phrases as idiomatic expressions such as “kick the bucket“, but they don’t have to have a special meaning, however it must function as a grammatical unit like “very happy” or “for twenty days”. So “kick the bucket” and “very happy” are phrases because we don’t know about the subject, e.g. who is “very happy” or is going to “kick the bucket“?
Adjective phrases are ones that modify an adjective which is already modifying a noun, so the adjective ‘happy‘ in the phrase “very happy” becomes either “a very happy man” or “The man is very happy“
Adverbial phrases are ones like “I’ll go to bed“, that can acquire a modifier adverbial phrase to make “I’ll go to bed in an hour“
Noun phrases are phrases with a noun, such as “Almost every sentence contains at least one noun phrase“, actually contains two noun phrases “Almost every sentence” and “at least one noun phrase“
Preposition phrases – English is a ‘head-initial‘ language (pre-positional), and it has a wide variety of words to express spatial and temporal relations normally built around a noun, e.g. “to his desk“, “in the kitchen“, “with chopsticks“, “on the top floor“, “inside the car“, “up the stairs”
Verb phrase – are composed of a verb and its object, complement and modifiers, e.g. “has finished the work“, “try that“, “has given”
Subordinate phrase – with words like after, as, as long as, because, before, every time, since, so, that, until, when, where, while.
Apposition phrases – usually concern two noun phrases, placed side-by-side, where one phrase serves to identify the other in a different way, e.g. “My sister, Pat Smith, likes jelly beans” consists of a noun phrase “My sister” with “Pat Smith” in apposition. This could equally be written “Pat Smith, my sister, likes jelly beans“, and in this case “my sister” would be in apposition to “Pat Smith“.
So as far as I can see syntactic categories include lexical categories and phrasal categories, and word classes are the same as parts of speech which are the same as lexical categories.
I’m really not sure why they call linguistics a science when there is so much uncertainty about basic definitions. And if you don’t believe me, have a look at the below ‘simplified’ mind-map of linguistic terminology.
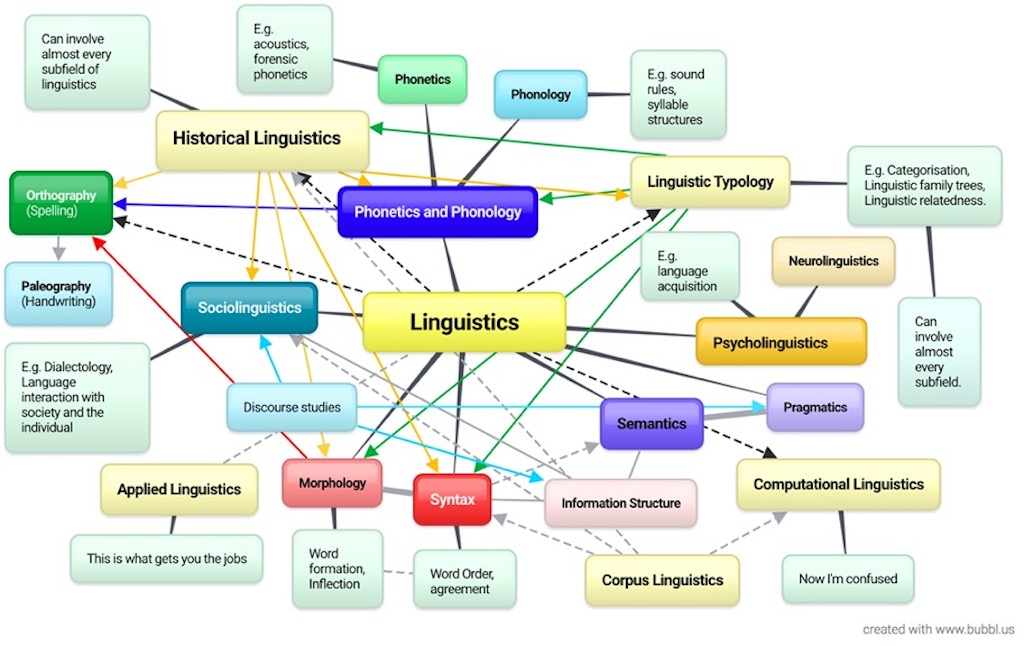
So I’m going to close this section with my best-guess for one-liner definitions:-
Language – a structured (grammar) system of communication, a set of symbols and sounds used in a regular order to convey a certain meaning
Natural language – ordinary language of humans
Spoken language – language produced by articulating sounds
Written language – representation of spoken or gestural language by means of a writing system
Linguistics – the analysis of language form (theoretical linguistics), language meaning (semantics), and language in context
Linguistic prescription – the attempt to establish rules defining preferred or “correct” use of language
Descriptive linguistics – objective analysis and description of how language is actually used
Applied linguistics – finding solutions to real-life problems related to language
Phonetics – the physical properties of speech (or signed) production and perception, with reference to a specific language
Phonology – sounds (or signs) as discrete, abstract elements in spoken languages used to convey linguistic meaning
Prosody – the properties of syllables and large units of speech, including intonation, tone, stress, and rhythm(the so-called suprasegmentals)
Morpheme – the smallest unit in a language that carries meaning
Morphology – words, how they are formed and their relationship with other words in the same language
Graphetics – the writing shapes as assigned to sounds or ideas
Graphemics – the study of language writing systems
Lexical items – single word, or part of a word, or chain of words that form the basic elements of a languagevocabulary (lexicon)
Word class (parts of speech) – categories of words (lexical items) that have similar grammatical properties, e.g. verbs, nouns, etc.
Syntax – how words combine (word order) to form grammatical sentences
Grammar – structural rules governing the composition of clauses, phrases and words in a natural language
Semantics – the meaning of words (lexical semantics) and word combinations
Discourse analysis – analysis of language use in texts (spoken, written, or signed)
Pragmatics – the way context and nonlinguistic knowledge contributes to meaning
Etymology – the history of words
Onomastics – the etymology, history and use of proper names
If I had to point to just one reference on the basic concepts of English grammar I would go for the work done at the University of Glasgow. And the Glossary of Linguistic Terms from the University of Birmingham was useful as well.
If you can't explain it to a six year old, ...
To misquote Albert Einstein, … I’m sure I don’t understand fully all of the above. It’s always a challenge when you come across a series of words that your not sure about, i.e. phoneme, grapheme, glyph, diacritics,…
In everyday life we don’t really need to know the meaning of these words, or even the notions behind them. Nevertheless, it’s irritating not to be able to place new words and concepts into a practical context. So here goes.
As an example, we do need a very precise meaning for these words (phoneme,… etc.) if we are going to understand some aspects of computer systems. The first term that comes to mind is the ‘character‘ on a screen, which has to do with orthographies and writing systems (Wikipedia provides an extensive list). As Wikipedia points out, a writing system is a way to visualise some form of communication, usually spoken. To do so you need some kind of script and a set of rules regulating it use. And the set of rules or conventions is called an orthography.
As far as I can see “script” means some way of “writing”, i.e. putting down something (recording) so that it can be understood (read) by others. Writing systems fall into three broad categories, namely alphabets, syllabaries and logographies.
So-called proto-writing came first, but they were just visible marks able to communicate very limited information. They were more like messages than a way to record the natural language of the writer. Initially a simple set of symbols were probably used to indicate an object or possibly an idea (e.g. the Tărtăria Tablets).
A logography is a written character that represents a word, which begs the question, What is a word? Firstly, a word of a spoken language is the smallest sequence of phonemes that have a practical meaning (always remembering that context also contributes to meaning). Which of course begs the question, What is a phoneme? A phoneme is a unit of sound that distinguishes one word from another, which means one part of the sound of a particular spoken word that when changed alters the meaning, and makes it a different spoken word. English, like many languages, was spoken differently in the past, and today there are also a multitude of different dialects in use (see list). But it’s generally considered that English phonology consists of about 24 consonant phonemes and between 20-25 vowel phonemes. So these phonemes are little bits of sounds that we string together to make the composite sound of a word. Anyway, back to logograms, Chinese-style characters (e.g. kanji in Japanese) are generally logograms, as are Egyptian hieroglyphics and cuneiform characters.
A syllabary, not surprisingly, is a combination of written symbols that represent syllables, or moras which make up words. And a mora is a basic timing unit of a spoken language, which is about isochrony, or the idea that every spoken language has some kind of rhythm. None of the languages I try to speak are syllabaries.
Finally, alphabets are written symbols or graphemes that we call letters, and these letters represent phonemes, at least for those languages that use the Latin alphabet, e.g. English, French, Italian, German, etc. So the idea is that each letter represents a basic unit of speech sound.
Unfortunately things are not that simple. The first things we do is to write down text, so that it can be read. An orthography is an agreement between the writer and reader on the method and rules of the writing structure, including things such as word order, spelling, punctuation, when to use capitals, etc. One aspect of the text is its informational content (the message), but the aspect we are interested in here is the physical form. For example, the lower case letter “a” used to write English, is an orthographic character. However, some orthographies contain elements that are a little more complex, using multiple components to write a single sound. For example, in Spanish, the pair of characters “ch” functions as a single unit, a single sound. This is an example of what is sometimes called a digraph, a pair of letters (characters) used together to represent one distinct sound (phoneme).
Above we mentioned ‘character‘ on a screen, in the sense of a computing character which we are told roughly corresponds to a grapheme and which includes the alphabet, numerical digits (0 to 9), punctuation, and the whitespace character. However, the mention of “ch” as being pair of characters, refers to them being symbols or glyphs. There are two definitions for ‘character’ provided by Wikipedia, character as a symbol (or glyph), and character as a unit of information (a grapheme). So what is the relationship between a grapheme and a glyph?
I’m using an entry on Quora that tells us that a character is the smallest component of written language that has semantic value, i.e. meaning. It is a concept rather than a particular way of drawing something. In this sense it is close to the Unicode Standard, our primary way of consistently encoding, displaying and handling text characters on computer screens. If Unicode considers it a character, it gets a unique number (codepoint), and if it has a codepoint it is “by definition” a unique character (in the sense that it is a unit of information and corresponds to a grapheme). So, letters, numbers, punctuation, accent marks (diacritics, see Wikipedia list) and many symbols are all characters. However, whilst all letters are characters, not all characters are letters. For example, there are an increasingly large number of emoji encoded (given unique codepoints/numbers) by Unicode (not to mention Linear B and even alchemical symbols). And in this context, a grapheme can be a single codepoint representing one character, or it can also be a sequence of codepoints that are displayed as a single, graphical unit that we recognise as a single element in our writing system. And as such, a text is just a series of codepoints.
A glyph is a particular visual representation of a character. In some cases a character might be represented by more than one glyph, or sometimes a glyph might represent more than one character. For example there is only one character T, but Times Bold and Courier Italic each have a unique glyph for the character T, namely T and T respectively. Where certain characters are joined together to make a more aesthetically pleasing shape, this is called a ligature. Some fonts contain special glyphs to replace specific sequences of characters, because they provide a better layout, in particular in script fonts. Below we have an example of five Zapfino font glyphs, the first four are pairs of characters, and the last is in fact a seven-letter sequence treated as one glyph.
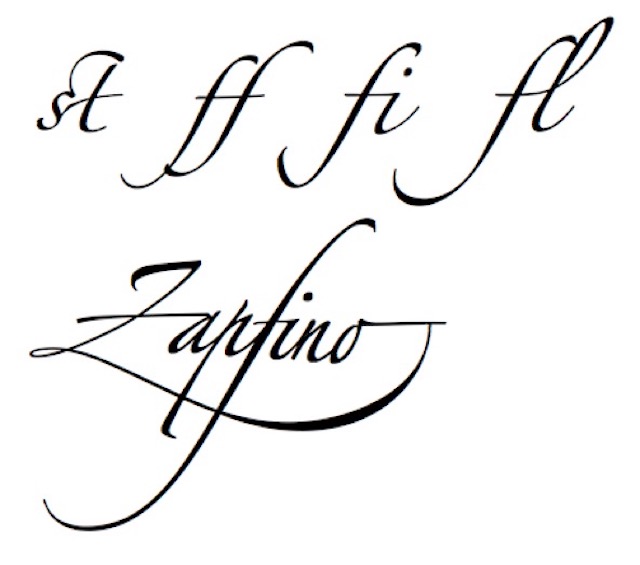
A grapheme is anything that functions as a character in a specific language’s written tradition, its “orthography“. In most cases, it is synonymous with a character, but not always. We mentioned that in Spanish “ch” is considered a single unit, so it is a grapheme in Spanish, but not in English. Similarly, “á” might be sorted and counted separately from “a” in the alphabet of one language (making it a separate grapheme), but in another language the same “á” might be just considered a variant of “a” (making it the same grapheme). A simple way to look at it is to think of graphemes as parts used to compose a character, and often a character might only need one grapheme.
A glyph is visual representations of a character and is usually stored in the form of a font, which is nothing more than a collection of glyphs, used to represent graphemes or parts thereof. And as we can now see, a font may contain multiple alternative glyphs for the same grapheme.
Splitting hairs, we have used the general understanding of the word font, but in reality the better term is typeface, which is not identical to font because the term font has historically been defined as a given alphabet and its associated characters in a single size. For example, 8-point Caslon Italic was one font, and 10-point Caslon Italic was another. So a typeface is the design of lettering that can include variations in size, weight (e.g. bold), slope (e.g. italic), width (e.g. condensed), and so on, and each of these variations of the typeface is a font. So in fact Zapfino would be a typeface, and what we see on our screen is one particular font of that typeface. This definition harks back to the days of metal typesetting, but with the advent of computer fonts, the term ‘font’ has come to be used as a synonym for ‘typeface’ even when a typical typeface continues to consists of a number of fonts. Zapfino makes extensive use of ligatures, and it is reported to also include over 1,400 glyphs.
With the ‘ff’ in Zapfino, the ligature of the two ‘f’ was represented by a specific glyph. More generally, this is an example of a digraph in a general class called a multigraph, for sequences of letters that behave as a single unit and not as a collection of parts. But what about ‘é’ in French, which is just a base ‘e’ with an ‘acute’ accent mark? We know ‘é’ is not considered a separate letter of the French alphabet, but are diacritics (accents) by themselves considered characters?
Firstly, ‘e’ is a character in the French alphabet, and ‘é’ is not (nor is è, ô, î, â, ñ, ü, ï, or ç). So in French, the accent floats above the character (or underneath in the case of the cedilla ç). However, in some languages ‘é’ is recognised as a character, because it is included in their alphabet.
I’m on uncertain ground here, but given that graphemes are the parts used to compose a character, one would assume that the French ‘é’ is composed of the one grapheme, the letter ‘e’, and an additional acute accent. In a language where ‘é’ was a letter of the alphabet, it would be just one grapheme. It is my understanding that Unicode, in addition to having a unique codepoint for all types of characters and graphemes, also has a full set of rules on how characters are composed. For example the Unicode for the base letter ‘e’ is U+0065, and for an acute accent ´ is U+00B4, but there is also a specific Unicode for é which is U+00E9, and in addition the Unicode U+0301 is for a combined acute accent, which means that it will form a combined grapheme with any preceding character, i.e. placing the acute accent on top of the preceding character.
In fact you can combine marks to form ‘grapheme clusters’ of almost anything since they will all glue together with the preceding character, creating x̧̞̥̖̉̄͑̕͘ , or the combined grapheme 가 from ᄀ andᅡ.
So a grapheme is anything that functions as a distinct unit within an orthography, and multigraphs (sequences of letters that behave as a single unit) are also all graphemes. But we have to remember that graphemes depend upon the particular orthography. If é is a separate character in the alphabet, then it’s a grapheme, but if it is simply considered a variant of e (as in French) it is not a separate grapheme in that language. Does that means that the French acute accent ´ is a separate grapheme? This depends upon whether they function as distinct units within the French orthography, so the answer for French would be no. But for some tonal languages acute and grave diacritics have distinct identities and purposes, and function in distinct elements in the orthography. In these cases, they would be considered distinct graphemes.
This discussion may seem very academic when someone adds with a pen, an acute accent over an ‘e’. However, it is vitally important in terms of what characters are in the domain of information systems and computers. The definition for a grapheme was dependent upon a given orthography, such that something might be a grapheme in one orthography, but not in another. The definition for character is equally dependent upon a given system, and it may exist in one information system, but not another. For example, a computer system may represent the French word ‘hôtel’ by storing a string consisting of six elements with meanings suggested by the sequence ‘h o ^ t e l’, the o ^ being two separate characters. Each of those six component elements is a character within the system, and are directly encoded as minimal units. Note that a different system could have represented the same French word differently by using a sequence of five minimal units, ‘h ô t e l’. The ô is a single encoded element, and hence is a character in that system. The two systems are different, but both are possible and, all other things being equal, neither is necessarily preferred over the other.
Up to now the characters we have considered are all visible, orthographic objects (or are direct representations of such graphical objects within an information system). In using computers to work with text, we also need to define other characters of a more abstract nature that may not be visible objects. The does produce an empty space between words, but we also need abstract “control” characters for things like carriage return, line feed, etc., which are used behind the scenes when working with text within a given computer system.
So now textual information in a computer system is composed of graphemes (characters) within orthographies, and abstract characters which are invisible but necessary. However, we have seen with ô that graphemes and orthographic characters can be represented by abstract characters in more than one way, and not necessarily in a one-to-one manner. And we have seen that there is a need for abstract characters that do not correspond to anything concrete in an orthography. To implement a system that seamlessly matches both real characters (graphemes) and abstract characters, it’s important to understand keystrokes, codepoints, and glyphs.
Keystrokes are the input method for creating data, which is then stored, and then rendered (displayed). A codepoint is merely the number that is used to store an abstract character in the computer. We have already seen the way Unicode assigns a unique hexadecimal number to each abstract character of a text (including control characters).
Glyphs have two distinct features, firstly the way they visually represent characters, and secondly, the way as graphic objects they are stored within a font. Basically, they are the shapes for displaying characters that you see on a screen or from a printer. In a simple sense, then, a font is simply a collection of glyphs, usually with common design characteristics. Since glyphs are contained within fonts, which are part of a computer system, glyphs are therefore a component within the domain of information systems, like abstract characters.
So, at the basic level, a glyph is different from a grapheme in that one is a graphic object located in a font within an information system, while the other is an element within an orthography. But there are other important differences reflected in the fact that graphemes and glyphs do not correspond to each other in terms of one-to-one relationships. We already saw that the English character ‘a’ can be displayed using any number of different glyphs. In addition, in a multilingual world, characters can be written using multiple shapes that are distributed around the shape for the initial character. So one glyph can appear in different ways for multiple characters.
It might then appear that the number of glyphs is determined by the character elements in an orthography and by their behaviours. But this is not necessarily true because the glyphs used in a font are determined by the font designer, and a font designer may choose to implement behaviours in different ways. The potential mismatch is avoided using unique codepoints that directly correspond to each and every character, including abstract characters. In a process known as text rendering, software takes a sequence of codepoints and transforms it into a sequence of glyphs displayed on a monitor or printer.
As an example, the English word ‘zapfino’ was stored as a string of seven characters, ‘z a p f i n o’, and was displayed using seven glyphs selected from a particular font and arranged horizontally (using information also found in the font to control relative positioning). In this case, there was a simple one-to-one mapping between the codepoints and the glyphs in the font. But let’s say that the font designer wanted to mimic more closely handwriting. After trying to understand the different ways to connect the letters together, the final outcome is a single, complex glyph for the entire word. The important message here is that there exist systems, sometimes referred to as “smart font” or “smart rendering” systems, that mediate between characters that are stored and the glyphs used to display them, and implements complex processes that give many-to-many mappings between sequences of characters and sequences of positioned glyphs, i.e. writing ‘zapfino’, the system might not simply produce a string of seven glyphs, but instead a single, complex glyph for the entire word (as was shown in an earlier example).
Now returning to our example of ‘é’, which can also be represented as e and an acute accent ´. The ‘é’ might be one grapheme in one language, but the composition of a grapheme and a diacritic in another language. Some texts call ‘e’ a grapheme base and a diacritic a non-spacing combining mark, or grapheme extender, and combined they create a grapheme cluster. Other texts note that the class of grapheme extenders also includes elements that do not create combined characters, e.g. placing the mark before the base character. And combined characters are defined only when an extender is added after the base character. We can see that this type of detail is important because it would affect how the rendering process needs to operate in order to generate the correct sequence of glyphs. However, the glyphs used to display this character sequence are still at the discretion of the font designer. It is still possible, for instance, to choose between a sequence of two glyphs or a single, composite glyph, and to have the rendering system handle the transformation from characters to glyphs. The point here is that a “smart” rendering system, that can support many-to-many mappings between characters and glyphs, makes it possible to have different implementations for a given writing system.
Native English speakers might think that this over complicates a “simple” language, but we must remember that English is actually full of loanwords. Different experts use different definitions, one has suggested that English contains more than 10,000 loan words, whilst another has suggested that 80% of English words are actually loaned from more than 350 different languages. Below are just a few English loanwords with different types of accents. And it looks as if the number is increasing since accents are being added to English words to give them an “exotic charm” (e.g. why stay in a simple chateau, when you can stay in a château, and it much more racy to read an exposé than a simple expose). This may look like a simple substitution of the French word, but how about choklët, pän, café or caffè, Brontë, blessèd, naïf, learnéd, Chloë, cliché, coup d’état, décor, maté, façade, Noël, über, latté or lattè, coöperative, entrepôt, …

And accents have their role to play, for example in French, divorce is different from divorcé, the first describes an action, and the second, a divorced man (a divorced woman is a divorcée).
Most professional-quality fonts include both a range of individual, floating accents and composite or prebuilt accented characters. Floating accents are used to create accented characters on-the-fly, while the prebuilt version is used as-is (see example below).

Prebuilt accented characters can be accessed either directly from a pre-established glyph panel or glyph list, or by using specific key combinations. Many more can be created on-the-fly by using key commands to add the floating accent to create the desired character.
The above collection of accents and accented characters are found in basic OpenType fonts, whereas below we have the much large selection found in OpenType Pro (but now only for accented characters).

This last section was added in order to try to better explain the relationship between phoneme, grapheme, glyph, diacritics,…, but if the reader would like to understand how the whole system comes together, including the treatment of non-Roman scripts, check out this article.