The 1970s
For me it all started in 1971 when I saw (figuratively speaking) my first big computer. I had a 6-month training period in a big UK nuclear research centre and I knew that there was a mainframe computer in one of the buildings. But I never actually saw it. My only contact was through someone who was playing Life on it. We would look at the printouts, and plan different geometric configurations as input.

At the time I was working in UKAEA Winfrith (B40) on the OECD DRAGON project (which included also the Euratom countries). I have no direct knowledge of the actually computer installed in building A34, but I have read that it was a ICL 4-70 acquired in 1969. It had 1Mb of main storage and 1Gb of online disc storage. It required a staff of 19 to run it, and was leased for £220,000 per year, plus a £30,000 maintenance charge.
A year later (1972), and in a different UK research centre (this time MoD), I had limited access to a big computer to produce Béla Julesz stereograms. Not the most challenging of tasks, but this time I could look through the glass window and actually see the computer, tape drives, and printers at work.

In 1972 I worked on the characteristics of second-generation night vision systems at a place called SRDE (Steamer Point). The Steamer Point site was famous at that time for its two giant Radomes used for satellite tracking (one 70 ft diameter and the other 40 ft diameter). It is quite probable that the computer I remember was the one used for controlling the tracking of the aerials.
Just as a bit of history, the site was home to a transatlantic link between SRDE and a US station in New Jersey using the world’s first satellites specifically designed for defence communication. And it was also linked to the world’s first geo-stationary defence communication satellite, the UK SKYNET I (made famous with Skynet in the Terminator film).
It was during this time that I first felt the conflictual relationship between programmer and computer system staff or ‘operators’. As these big computers moved in to the public domain they were called ‘data processors’ and at that time management tended to focus on getting the best new technology and not on running the place like a ‘shop’ where they had to provide a service to their users.
Programmers did not have physical access to the computers, but felt that they were in command and could (or should be allowed to) do what they wanted. Without programmers, computers were useless. Users (programmers) would criticise operators for what were actually computer system failures. Often operators were poorly trained and treated as technicians. They felt that programmers were treated as professionals and had all the privileges (offices, easy working hours, better pay, career development…). The operators certainly felt that the computer was theirs since they kept it working. Programmers felt that computer technicians acted like priests (my words) of a new religion, and that programmers were just allowed to worship (my words) provided they accepted the rules and rituals. I saw the computer room as a kind of modern cathedral (silent, cool, imbibed with symbolism). I still think that this ‘cultural conflict’ is at the root of today’s (non-criminal) hacker mentality. A good programmer hates the answer “you can’t, the system does not allow it”.
We have to remember that we are talking about the 60s and early 70s. Computer science did not really exist. I think that the first true computer science PhD was awarded in 1968, and the first computer science graduates appeared in the US in 1972. I think that it was possible to do a one-year graduate course for ‘postgraduate instruction in numerical analysis and automatic computing’. But well into 70s computer programmers were recruited from graduates in mathematics or physics. So in the early days computer operators were lower paid technicians, whereas ‘programmers’ were university educated professionals (academics and research scientists with specialist skills in other fields).
This was just the beginning. Because both parties had control over a powerful new technology, and they were both granted an unprecedented degree of independence and authority. Both were vague about the formal structures under which they worked, and there were very few sensible sounding job titles. Often companies purchased a computer without really knowing why, and often they had little idea what went on in the ‘computer department’. This brought both programmers and operators into conflict with established networks of power and authority.
This was particularly true when the computer moved out of the research and military laboratories and into the corporate environment. The computer changed from being a machine to run highly optimised mathematical routines, and became an ‘electronic data processing’ machine for information management. In some cases existing departments inside a company would plant spy’s as computer operating staff just to find out what was going on. Newly recruited programmers with good university degree’s were often shocked by the low-quality work environment. Existing staff were worried and reacted badly to the arrival of both ‘programmers’ and ‘operators’, and they often disliked their unusual work timetable and dress codes. Programmers were professionals and many in traditional management roles expected them to look and dress accordingly. We need to remember that the vast majority of management staff in a company in the 50s, 60s and 70s didn’t have university degrees. Programmers were also quite young, but appeared to acquire privileges usually reserved for older member of staff, e.g. no need to clock in and out. Often the computer departments were not well integrated into the company, and thus programmers were on the one hand quite independent, but on the other hand quite isolated. Operators and programmers working long and unusual hours would earn quite a lot of overtime (up to 30%-40% of their salary), which also upset established managers who took home less money.
The first application of a computer in a company was usually for inventory or stock control, and this set programmers against the stock controllers. Programmers saw stock controllers as idiots, and stock controllers saw programmers as not understanding the way the company worked. Programmers were arrogant and would lecture company staff in mathematics rather than explain how a computer could be of everyday use. The programmers worked to master the complex tasks within a stock control situation, and they would produce lots of ‘output’ which was then ignored by stock controllers. They would try to impose redesigned clerical procedures on to stock controllers. They replied by describing how they did their work, and asking that the programmers use the computer to support their workflow. Oddly enough in the 50s programmers felt that workflow diagrams were a waste of time. We need to remember that in the period 1957-58 only about 100 computers had been ordered by all UK companies.
Already in the early 60s things started to change as both programmers and stock controllers started to look at real problems such as stock backlog, etc. The key was that finally the programmers developed systems that helped stock controllers make better decisions. These decisions saved money for the companies, removed a lot of the clerical drudgery and above all improved the status of stock controllers, making them more involved in merchandising.
So the bottom line was that initially the computer was just another tool to be managed, but it quickly became a tool for management. And computer specialists became ‘change agents’.
As the role of the computer changed, there emerged a whole new ecology of computer specialisation, with analysts, operators, researchers, system managers, data processors, etc. By the 80s almost everyone working with computers had a degree in computer science, but that did not make them computer scientists. Still today computer scientists write code (mostly mathematical) but they do so only to prove that it works. Programmers (should) make clean, well-documented, and error free code. Their skill is less mathematically, and more procedural and algorithmic. Developers or software engineers aim to pull together all the different bits of code (applications) in order to satisfy a client (company requirements, etc.). Software engineers are often (just) responsible for maintaining systems.
Some historians want to go back even further. The first programmers were women, or ‘girls’ who were ‘human computers‘ (see this video and this video). Women were recruited to ’setup’ the earliest computer machines (e.g. ENIAC) for specific computations (see video). The terms software was only introduced in 1958, but these women were the first software workers. The term was used to differentiate between the male-dominated ‘hard’ technical mastery, and the ‘soft’ business of the women who kept the machines working. But it was these women who were the first computer programmers, i.e. setting up the machine to perform the predetermined calculations (see video). Often the earliest machines looked like cable-and-plug telephone switchboards, reinforcing the idea that the programmers were just machine operators.
Even John von Neumann distinguished between ‘headwork’ for male scientists or ‘planners’, and the ‘handwork’ of the female ‘coders’. Coding was manual labour, translating the work needed into a form that a computer could understand. This picture actually turned out to be quite different in reality. Programming was far more difficult, time-consuming, and expensive than initially imagined. The hidden complexity became a new intellectual challenge. In fact in the very early days programming was a ‘black art’ and it was only in the early 60s that it started to mutate into the science of software engineering (with Fortran (video) introduced in 1957 and COBOL in 1959).

In 1975, at yet a different nuclear research centre, I first saw a simple hand calculator for the first time. I had to have one. It was a 4-function calculator with a memory, very similar to the one above. I actually never got one, because they were far too expensive even for someone living on a good student grant.
But soon enough (ca. late-1976) I bought a Sinclair Cambridge Scientific like the one below. Initially it cost about $80, but by 1976 the price had dropped to about $15.

I can still remember doing my A-level in Statistics (1969-70) using a mechanical hand calculator like the one below (photograph with the covers removed).

During the period 1975-1977 I was working in the Biology Dept. in JRC Ispra, Italy (see for example, the “Fifth Symposium on Microdosimetry”, 1975). This research centre also had a big computer centre (CETIS). However, my research did not require any major computational skills. I knew that it was home to an IBM 360/65 (see video), and that one of its main tasks was to provide reactor shielding and nuclear data for reactor design and safety calculations.
If my memory serves me correctly, there was also a program to link different science research establishments around Europe. EURONET was the predecessor of the packet-switch network implemented by the PTTs. DIANE (Direct Information Access Network for Europe) was an information service network that eventually provided online access to some 200 databases operated on 24 host computers around Europe. In the mid-70’s a search using one of the earliest specialist databases could cost $20-$40 per search. There were only a few networks at the time, and each had a user base of about 100,000-200,000 searches per year.

I also know that from 1970, CETIS was already involved with practical Russian-English machine translation with Systran. And by 1975 there was a collaborative research program on multilingual systems in support of the European Communities translation services.

The IBM Personal Computer was a reality in 1981, but the first memory I have of a portable computer (more ‘luggable’ than portable) was seeing in the same year the Osborne 1 (the Apple II first appeared in 1977). All these early computers were far too expensive for me. I remember hearing for the first time the expression “the computer you really want always costs $5,000”.
During the period 1977-1978 I needed to perform some relatively simple calculations (whilst working in yet another research centre, this time in Germany). I used a desktop HP-85 and learned to programmed in BASIC. I also worked with someone having access to a mainframe. He did all the hard work, but it gave me the opportunity to learn Fortran.
The reality was that I had decided that I was not going to follow-up on the topic of my PhD studies (for reasons too complicated to mention here). But I needed to acquire a new skill, and ‘scientific’ computer programming was the easy option. The research centre was running courses, and I had almost unlimited access to the mainframe. I didn’t have a preferred scientific topic, so I focused on learning everything about Fortran, and as much as I could about assembler and even machine code.

As luck would have it, during 1978-1979 I returned to the JRC Ispra in Italy with the specific task of performing reactor physics calculations. This involved making modifications to existing computer codes written in Fortran. The process was simple. Make the modifications, run the modified codes, take the results and hand process some of them as input to a new calculation with the same code, and do this for multiple configurations and burn-up cycles.
At the time I used ORIGEN developed in Oak Ridge to calculate nuclide inventories, followed by APOLLO for space and energy dependent flux for 1- and 2-dimensional problems, then a custom reactor physics code developed by CNR in Bologna (I think it was called RIBOT-5A), and finally a 2-dimensional transport code TWOTRAN (also the 2-dimensional diffusion burn-up code EREBUS comes to mind). The question was to both extend the codes for input vectors including actinides, and for very high burn-up. Calculations were benchmarked against measurements made on high burn-up fuel pins from Obrigheim, Gundremmingen, Caorso, and Trino Vercellese.
At the time, input to the mainframe was made using a tray of punch cards (see this video and this video). Each punch card was one line of code. I would go to the computer centre, punched out the new cards I needed (changes to code or new input data), and put my tray through a small window. Access to the computer itself was strictly controlled, and all the computer hardware was in a large air-conditioned and dust-free room. Through the small window I could occasionally see people working in white coats, etc.

Each tray of cards (a code or program) would go into a waiting queue, and the first problem was that I did not know when my particular program would be run. I remember working on the basis of 4 hours, and hoping that I could get two runs a day, plus one overnight. Naturally I could put in multiple versions (different stacks of computer cards), but system staff were there to ensure that everyone got a fair share of cpu time.

My office was a good 10-minute walk from the computer centre, so after about 4 hours I would walk (rain, shine, snow, etc.) up to collect the results. The tray with the punch cards, and the printout would be in a pigeon hole. Or not!
With some luck I could ask through the window in the wall if there was a problem and did they have any idea when my program would run. Problems occurred quite frequently, and the input queue could be more or less long, etc. So it was a bit of a lottery. Rather than walk back to the office and then return later I would wait. I almost always had a second or third code that needed some new punch cards.
And in the building there was a small coffee shop, which was home to many people waiting for their codes to run. I could spend a useful half-hour there picking up tips and chatting about problems. Since all the pigeon holes were visible, people would pop-by and mention that my printout was in. I would do the same for them before walking back to my office with my treasured results. Some days I might drink 7-8 strong Italian expresso’s (plus one after lunch).
Naturally there were bad moments when instead of a 2”-3” stack of paper, I saw only a few pages waiting for me in my pigeon hole. This meant that something had gone wrong, and that I had stupidly lost half a day. The computer codes and the calculations, etc. were full of intermediate steps printed out. This was so I could see exactly where the error occurred, and home-in on it immediately (without going back to my distant office). Naturally this did not always solve the problem, I could then be hit by another error embedded in a later part of the code or data input.

Getting a full printout did not mean that things had worked out correctly. Checks had to be done, ‘common sense’ applied, and results benchmarked against experimental data. I, like everyone else, kept the printouts, marked them with cryptic codes, and stacked them along my office and nearby corridor walls.
Once the results had checked out I then had to hand calculate new input vectors for multiple fuel configurations and burn-up cycles. By hand each calculation would take about 90 minutes (and a bit extra to double-check). This meant that I could not expect to run my codes 3 times in 24 hours. I quickly turned to a “old” laboratory computer for help. This was an Italian-built Laben mini-computer (see below).

The advantage was that it was available to me 24/7. The disadvantage was that it had to be booted by hand. The first step was to get it to read the boot paper tape. This involved inputting a string of commands through a series of buttons on the front of the rack. Without going through all the procedure the result was that I could run a small program that I had written in Basic. Inputting the start vector on the teletype terminal, produced a simple printout of the end vector. The input vector was the nuclide inventory at the end of a reactor cycle, and the output vector was the same inventory after a specific period of cooling, usually 3 years. After some checks, this end vector became part of the input data file for new runs of the codes on the mainframe, i.e. for actinide re-cycling and burn-up.
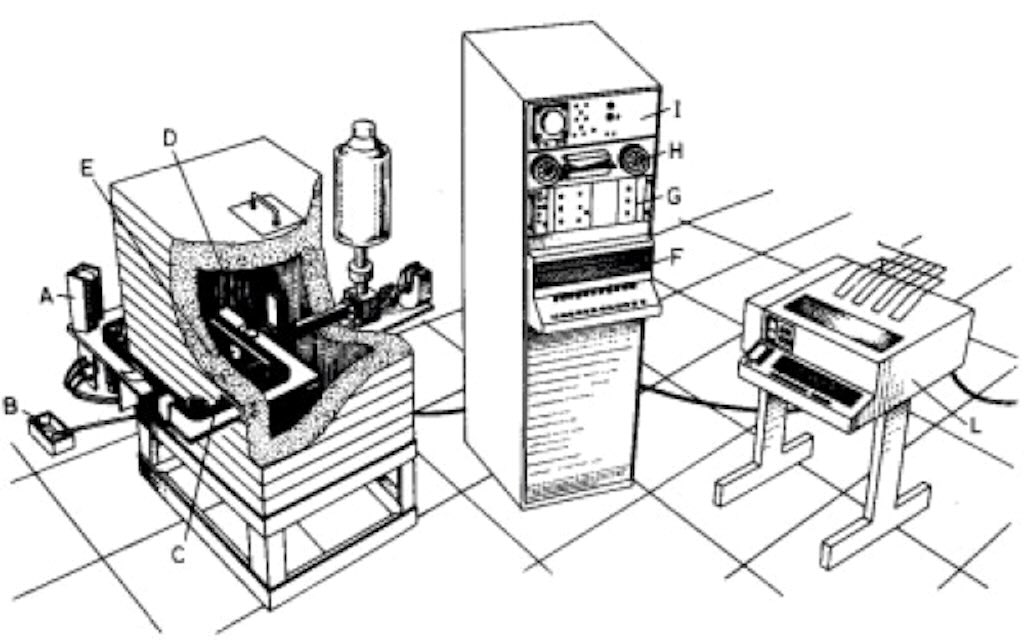
What we have above is the measurement system used in Ispra in 1973. The whole system had been decommissioned by 1978, but the mini-computer and teletype (TE300 from Olivetti) were available and still working. The Laben company actually stopped making minicomputers in 1974.
The LABEN 70 was a 16-bit machine, with a 32 kbyte memory. I think it ran at the incredible speed of 0.7 MHz. I remember it used a so-called POS (a paper tape OS, as opposed to a later magnetic tape OS). It also had a small mathematics library and a BASIC interpreter.
My world chanced with the introduction of TSO (Time Sharing Option). In practice this meant that in our building a terminal was installed (and I mean just one terminal installed in a “terminal room”). During my stay this terminal only had one function. It told me where my codes were in the input queue, and if they were finished. The gain in time was enormous, and my consumption of coffee dropped to a civilised level.
With a colleague and great friend S. Guardini we published “Calculations for the assessment of actinide transmutation in LWRs” in the Proc. 2nd. Tech. Mtg. Nuclear Transmutation of Actinides, Ispra, 1980. The original has been lost, however we are still referenced in a report on Actinide Transmutation in Nuclear Reactors (1995).
During my time in this research centre I came across a instrument-dedicated mini-computer. I’m not sure who made this mini-computer but I remember someone saying that it ran at the fantastic speed of 2 MHz (ca. 1978-79).
According to what I remember microprocessor speeds hit 2 MHz in about 1977, and only got past 3 MHz in about 1982. I think the earlier processor was the Intel 8086 which hit 1 MHz in mid-1978, and the Intel 80296 only hit 3 MHz in 1982. Microprocessor speed is a tricky concept. The 8086 was marketed at 4.77 MHz in 1978 (and cost around $90 each), but one instruction actually takes many clock cycles, e.g. just dividing two numbers could take between 80 and 190 clock cycles, and the time to compute and register something in a memory slot would take between 5 and 12 clock cycles. The Intel 80286 was slow to market because of the high cost in adding extended memory, and the fact that it was not backward compatible with previous microprocessors.
So a front end pulse counter (microcomputer) able to count and store in excess of 1 million pulses per second was world-class.
In order to take advantage of its phenomenal speed it was programmed in machine code (not even assembler) for one very specific task (counting pulses from a detector array and placing them in time-tagged ‘bins’). I think that it was in 1979 that it was attached to a PDP-11 which was dedicated to processing the output from this front-end processor. See “Interpretation of plutonium waste measurements by the Euratom time correlation analyser” (IAEA-SM-246/50) page 453.
I think many people do not realise that to produce an academic paper for a conference was a major undertaking. With luck you might have the text typed into a word processor system. This allowed you to make changes with relative ease. Tables, mathematical formulas, etc. were impossible for these early word processing systems. And there were no graphic packages, so all the data was usually just printed out, and you had to make your graphs by hand using pens and stencils (see the really good example below).
Then came pen plotters. Initially they were big expensive x-y plotters, but in the early 80s HP produced small and lightweight desktop peripheries. This was fantastic because you could make (and re-make) elaborate and very professional looking graphs and diagrams (see below).
Finally once you had all the bits printed out, it was just a question of scissors and glue to get it all on to the conference paper template. And for the presentation it was all about printing the key elements onto a set of transparencies for an over-head projector.
So it is not surprising that early PC software packages were welcomed with open arms, e.g. VisiCalc (1979), WordStar (1978), dBase (1979), WordPerfect (1979), and later Lotus1-2-3 (1982) and MS-Word (1983), and finally LaTeX (1985) and PowerPoint (1987).
During 1979-1981 I worked in a French university research institute where they had access to a CDC mainframe. My work was to write programs that were transportable to mini-computers which were dedicated to specific measurement systems. Not the most passionate of tasks, and I spent most of my time sitting in front of a screen in the terminal room.
It was at this moment that I decided I was not going to be a research scientist. Realistically there were many things I could not master, and what I could do was becoming increasingly boring. I could not imagine spending the next 35 years writing scientific code for computers.
The 1980s
In June 1981 my work focus changed dramatically, but by then the computer was starting to become a part of everyday work (note that I did not write everyday ‘life’). In June 1981 we were still in the world of typewriters, albeit electric. My first memory of the ‘computer’ arriving in the office was with the new generation of WANG word processors (possibly selected because it could handle both English and French). In many ways it is wrong for me to associate word processing with computers. The reality was that computers were for calculating, whereas word processors were just glorified typewriters. It was IBM that developed the Selectric typewriter and even defined the concept ‘word processing’ (from German ‘textverabeitung‘ coined in the late 50s). Word processing and computing would merge years later, probably with the introduction of WordStar in 1979.
So from mid-1981 I no longer worked directly with computers and computer codes, but over time they would become just another tool in my working environment.
Nevertheless, there were a few early “highlights”, namely:-
- I remember that sensitive data were either hand-encoded or delivered on magnetic tapes. Once per week the tapes were taken to a mainframe, and because of the sensitive nature of the data, it was switched off, and rebooted just for processing this data during the evening. I’m not aware of the full process but it is symbolic of the rare nature of computing infrastructure even during the early and mid-80s.
- We increasingly needed to attached computing hardware to instruments (see below for a ‘modern’ measurement system for the 80s), but to purchase such hardware we needed to go through a complex process involving a special committee to vet all computer purchases. We ended up preferring to use small HP machines as “instrument-dedicated desktop calculators” and buying them along with equipment purchases.
- In ca. 1984-85 you could have a PC-clone at home, but if you had one on your office desk you were considered privileged. On top of that I remember that the office Olivetti PCs cost more than twice as much as a really well equipped PC-clone bought on the open market.
- I will not describe the equipment shown below. But it was designed specifically for our needs, was built in quantities of one or two, and would cost close to $100,000 each. I wonder what they cost now? Check out these publications to get a feel for what was going on at the time.

Mini-computers (or even personal computers) could in many ways rival mainframes. They were relatively cheap but had limited processing power. However they could be dedicated to performing a specific calculation that might only taken a few minutes of cpu time on a mainframe. The problem was that you might have to wait for hours for your program to get a slot on a mainframe, whereas your mini-computer was sitting on your desk dedicated only to your specific tasks.
In the later 80s we inherited an old computer building with its computer room. We had to make major alterations to air conditioning (to stop the fixed 18°C working environment), to natural lighting (totally absent), to the floor (which was designed to house all the cables and was not load bearing), and to the electric supply (which was uniquely customised for computer hardware).
Part of the computer room was still dedicated to a small Siemens ‘mainframe’, but it took up perhaps 10 square-meters, and looked a bit stupid stuck in the corner of a 150 square-meter old-fashioned computer room. But even in bureaucracies, size counts. A big computer room (even 90% empty), which no one was allowed in, meant that you were important.
Of course today computing hardware covers everything from supercomputers, mainframes, minicomputer servers and workstations, microcomputers both desktop and laptop, mobile computers such as iPhones, and all sorts of programmable logic controllers and embedded microprocessors.
The 1990s
In 1992-93 I changed jobs again, and immediately came into contact with the non-nuclear worlds of computing in media and information technology (IT). The first task of every new IT project appeared to be the purchase a Sun SPARCstation (below and this video), and everyone in the new media projects got Apple laptops. They were like status symbols.

During the 80s, as prices fell, the computer gradually migrated from the working environment to the home environment.
Initially people did not really have computers or microprocessor-based systems in the home. You did not go home to your computer. Computers could be a passion, but they were a work passion. However, according to a report, by 2006 there were about 50 microprocessors in an average middle-class US home. They also noted that if you added portable equipment such as games, phones, music players, etc., plus a couple of cars, the figure would be about 200. Today many cars are home to more than 100 microprocessors, and the most data-intensive in-car application is the collision avoidance system. Put two of those cars in a garage and you will have the same computing power as ‘Blue Mountain’, the worlds’ top supercomputer in 1998.
My first purchase of a personal computer was ca. 1987. I ordered it from the US, and it was a so-called “no name” or PC-clone using the Intel 80286. If I remember correctly my next computer was a 80386-based clone also bought in the US ca. 1991. I know my third no-name PC was a Pentium-based machine bought in ca. 1995. This time I bought it from a local shop that sold all the components. I then put my ‘ideal’ machine together myself. This meant that through to ca. 2000 I could upgrade my home-based PC at will.
As my job evolved I increasingly found myself called to make presentations whilst travelling. I sold my home-based PC clones and in 2000 I bought my first portable, the ultra-slim notebook Sony Viao 505. In late 2003 I bought the same model at an end-of-series discount price.
Beyond 2000
Sometime in late-2005 or early-2006, it was time to migrate from DOS to the Apple Mac. Over the years I had watched the arrival of Apple II, Lisa, etc., but finally I committed to a 17-inch MacBook Pro.
I must say it was a fantastic machine, but it took me few weeks to adjust to the Mac OS. However I found the ‘portable’ just a bit too big and heavy. In mid-2012 I moved to a 13-inch MacBook Pro ‘laptop’, and since then I’ve stayed with this format, and I’ve always been able to sell my older machines.
For a short period of about 18 months (2013-2015) I also had a 21-inch iMac, but portability won out.
Most recently I’ve migrated to a space-black M3, but, age obligé, increasingly it’s the quality of the 32″ monitor that counts.
In 2012 I bought an iPad in the Apple store in Caesars Palace, Las Vegas. I still remember it costing the same price in $ as it cost in £ in the UK. I also remember not being that convinced with the iPad concept, but the discount was too good to miss.
However, in 2017 I bought a new iPad and I’ve used it almost everyday since then. They are fantastic machines for email, Web, Skype, WhatsApp, etc. (also Facebook, LinkedIn, etc, but I stopped using them in 2016).
Mobile Phones
I bought my first mobile phone in 2001. It was a Nokia 3310, and I still remember leaving it in a taxi in Barcelona.
My next mobile phone was the cool clam-shell Motorola StarTAC, bought in 2003, and lost on a ride in Disneyland Paris.
My next mobile phone was the fantastic Sony-Ericsson K800i. Bought in 2006, I still have it, and it still works (last time I tried in 2020).
The very first iPhone was released on 29 June, 2007, and it cost $600. Only 8 years later more than 1 billion people owned and used a smartphone (it was in fact Ericsson who first marketed a ‘smartphone’ in 2000).
Looking back people tend to forget that the iPhone only started to sell well in 2008 when Apple came out with the iPhone 3G at $200. The unique selling point at the time was that the iPhone was a phone, a music player and a personal organiser, all in one device. Apple had the touchscreen (which was really cool at the time), and they had software (apps) specifically designed for their device.
But the key was that Apple controlled the operating system, so they controlled which carrier (phone company) could use the iPhone and which software applications could run on it.
You could unlock (jailbreak) it, but then Apple could issue software updates that effectively re-locked it again. The jailbreak community showed that there was a major market for 3rd-party apps. As of 2019, the App Store now has more than 50,000 apps, and more than 1 billion have been downloaded.
In many ways the smart bit of the iphone already existed since the mid-90’s in the form of a personal digital assistant. I had owned a Psion 3 from about 1994 through to when I bought the Nokia. It was incredible rugged and stable, but I never really exploited its full potential.
In Sept. 2009 I moved to the iPhone 3, then to the iPhone 5 in Oct. 2013, the iPhone 6 in Aug. 2015, the iPhone 8 in late 2018, and until recently I used an iPhone 12 Pro. I must admit I don’t (yet) see the need to upgrade, but I’m sure a time will come (yes it did and I have new iPhone 16 dated 2025).
However, I must also admit I have migrated away from using the iPhone as a camera (and back to my Sony Cybershot). The reason is simple. The iPhone has become so important as a kind of “ID” for payments, etc., that I can’t afford to lose it, or have it snatched. People who are waving their iPhone around or taking selfies at arms-length are asking for it to be grabbed by someone on a bike or scooter.